
标题: DeepSeek-V3.2-Exp: Boosting Long-Context Efficiency with DeepSeek Sparse Attention[1]
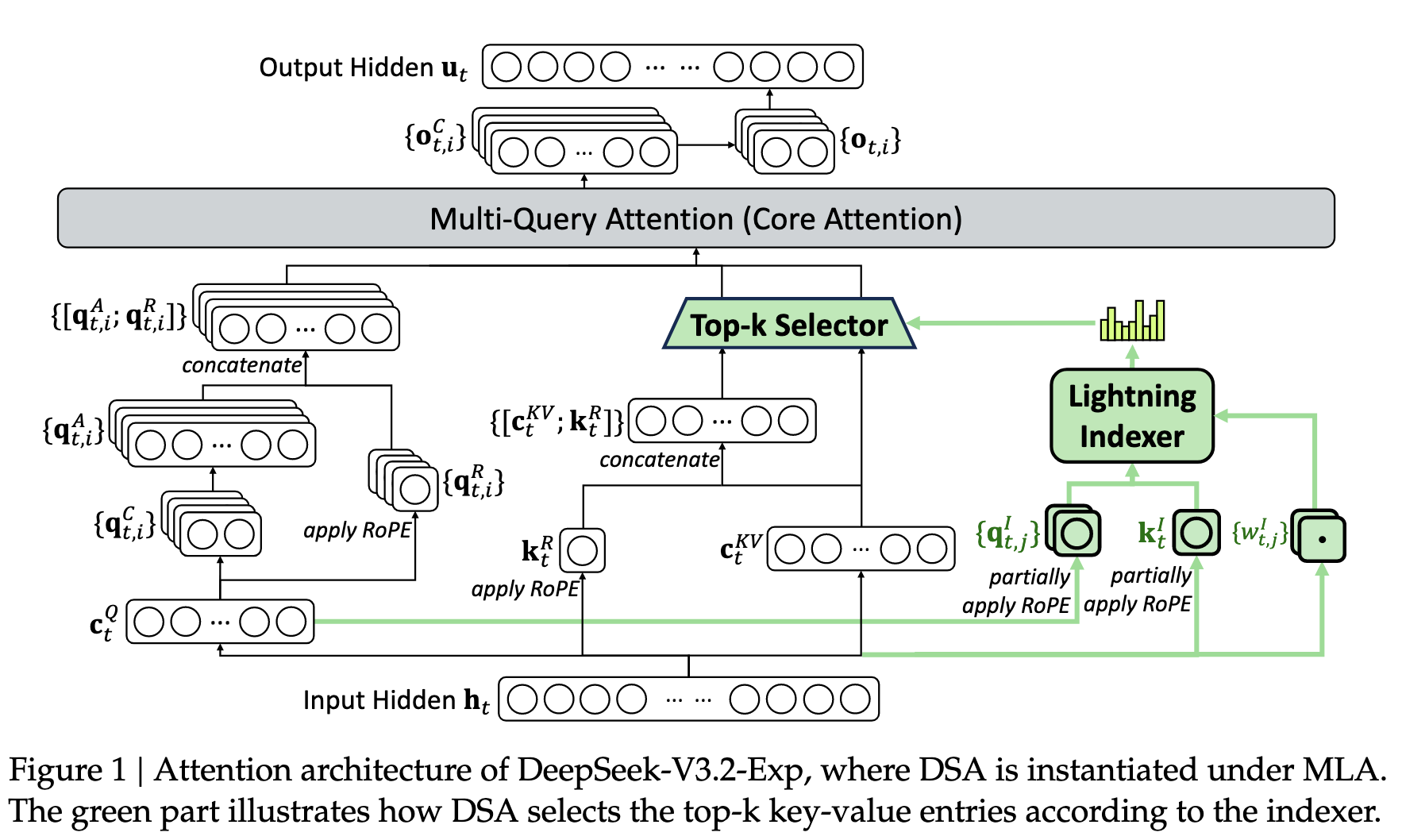
使用 Deepseek Sparse Attention 在没有明显降低精度的情况下大幅降低推理成本。
1. 模型架构
和 Deepseek V3.1 Terminus 相比,增加了 Deepseek Sparse Attention(DSA) 模块。DSA 就是在 MLA 的时候,先计算一下 qk 的 score,然后根据 top-k 的索引选择出最终进行 attention 的 kv。
主要有两个关键部分:
-
lightning indexer:计算 qk 的得分。
-
fine-grained token selection mechanism:选择 top-k 的 token。
\[\mathbf{u}_t = \text{Attn}\!\left( \mathbf{h}_t, \left\{ \mathbf{c}_s \mid I_{t,s} \in \text{Top-k}(I_{t,:}) \right\} \right)\]
从 V3.1 Terminus 继续训练。相当于修改了原始模型的结构,利用原始模型的参数。
2. 训练
2.1 Continued Pre-Training
训练数据的分布与 V3.1 Terminus 使用的 128K 长上下文扩展数据完全一致。
分为两个阶段
-
-
short warm-up stage 来初始化 lightning indexer 的参数,同时冻结其它的参数。 -
为了对齐 indexer 和 attention 的输出分布,对于 t-th query token,统计所有 attention 的和,然后对这个和做 L1 正则(sequence 维度)来生成目标分布 p。然后使用 p 和 indexer 的 KL 散度作为训练 indexer 的目标函数。Dense Warm-up Stage
\[\mathcal{L}^I = \sum_{t} \mathbb{D}_{\text{KL}} \left( p_{t,:} \parallel\text{Softmax}(I_{t,:}) \right)\]
-
-
Sparse Training Stage 相对于 Warm-up 阶段,只是将 attention 的目标函数修改为了 sparse attention
\[\mathcal{L}^I = \sum_{t} \mathbb{D}_{\text{KL}} \left( p_{t, \mathcal{S}_t} \parallel \text{Softmax}(I_{t, \mathcal{S}_t}) \right)\]
2.2 Post-Training
和 V3.1 Terminus 用了一样的 post-training pipeline
-
Specialist Distillation 训练了 5 个专家模型:mathematics, competitive programming, general logical reasoning, agentic coding, and agentic search。生成 long CoT response data 和 direct response data 进行训练。 -
Mixed RL Training 使用 GRPO 算法。合并了 推理,agent,human alignment 到一个 RL 阶段来避免灾难性遗忘。 奖励:
-
resoning 和 agent 任务:基于规则的奖励 -
general task: 生成式奖励模型
奖励设计平衡了两个关键权衡: (1) 长度与准确性 (2) 语言一致性与准确性
-
3. 评估
3.1 模型能力
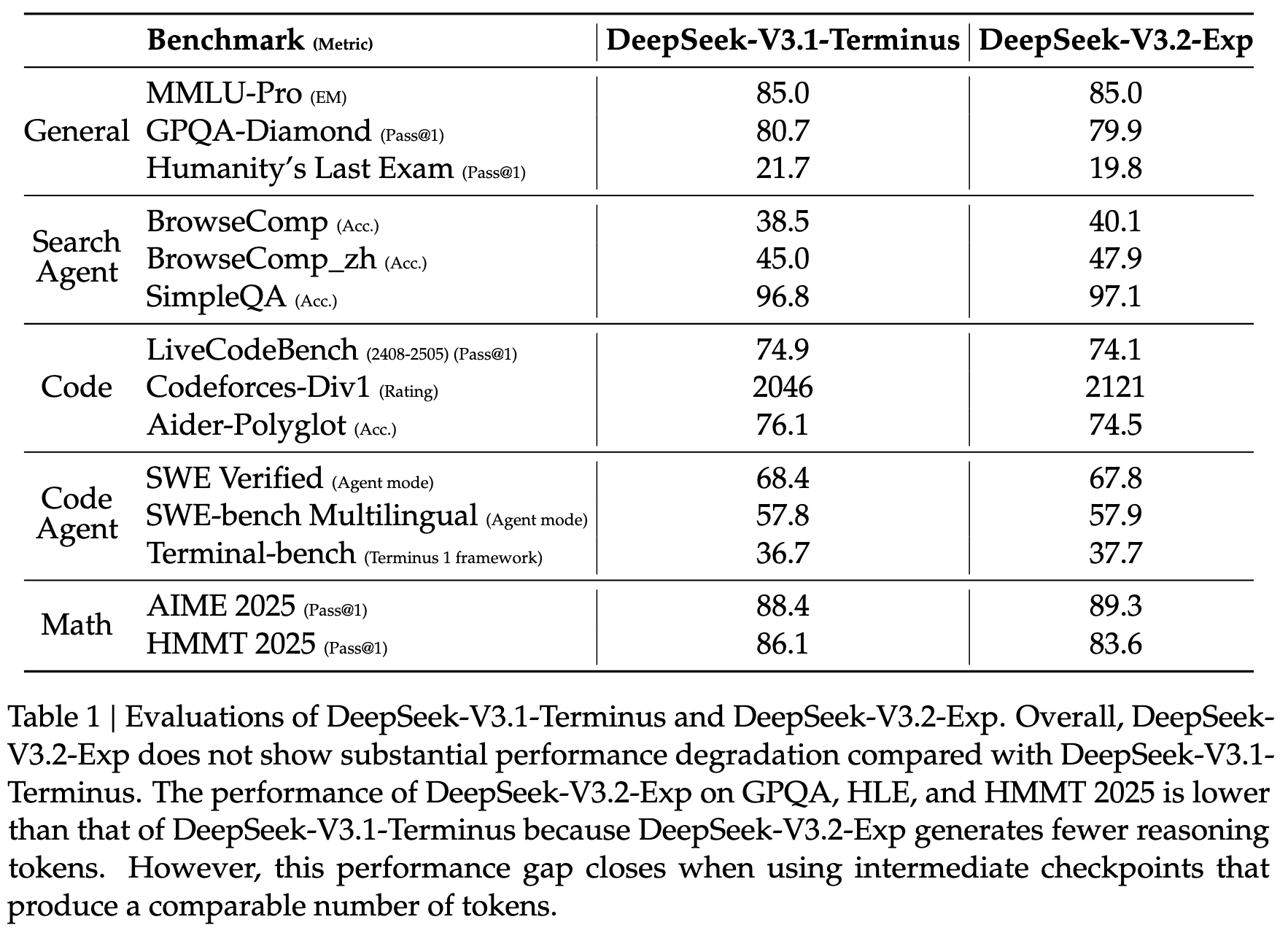
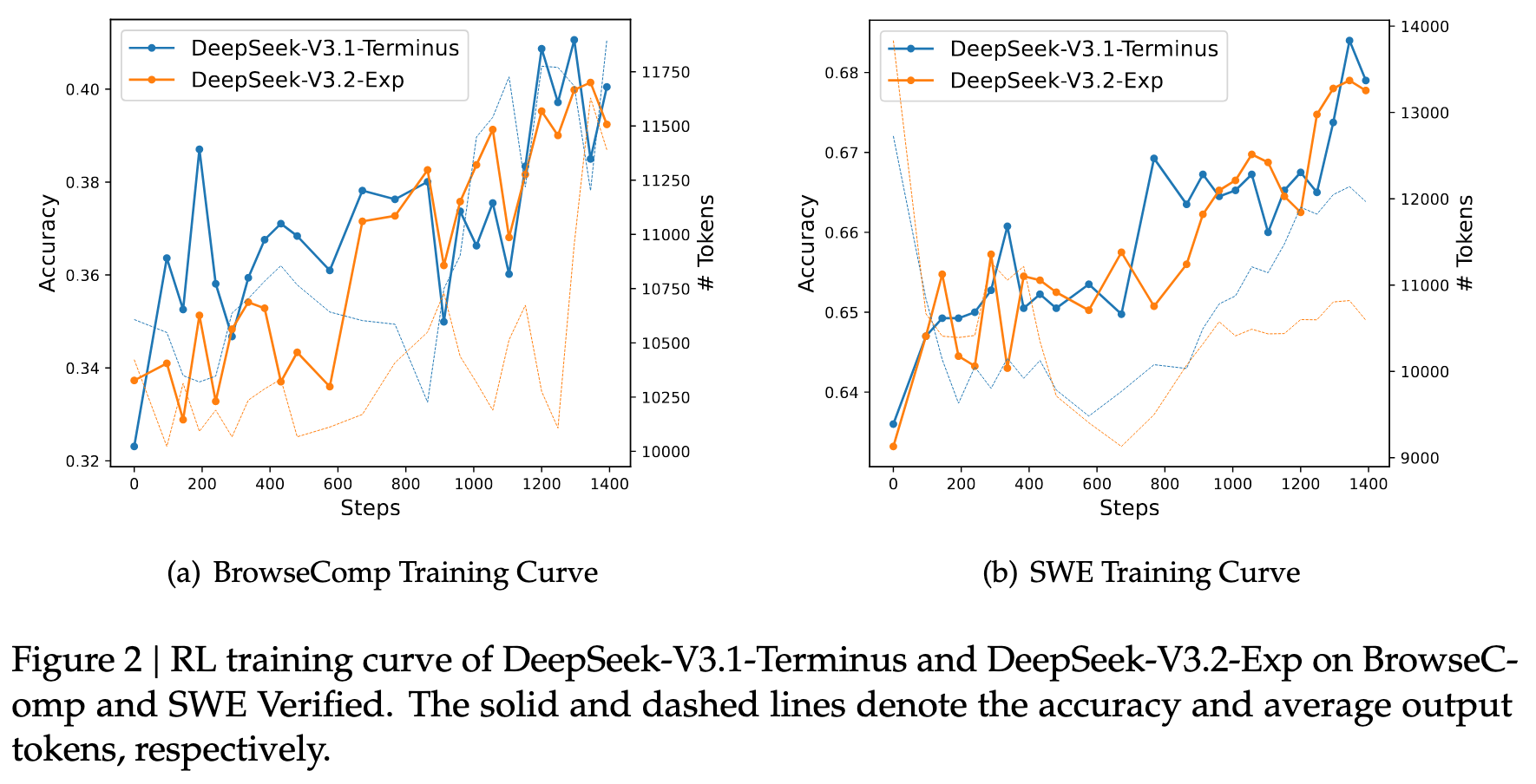
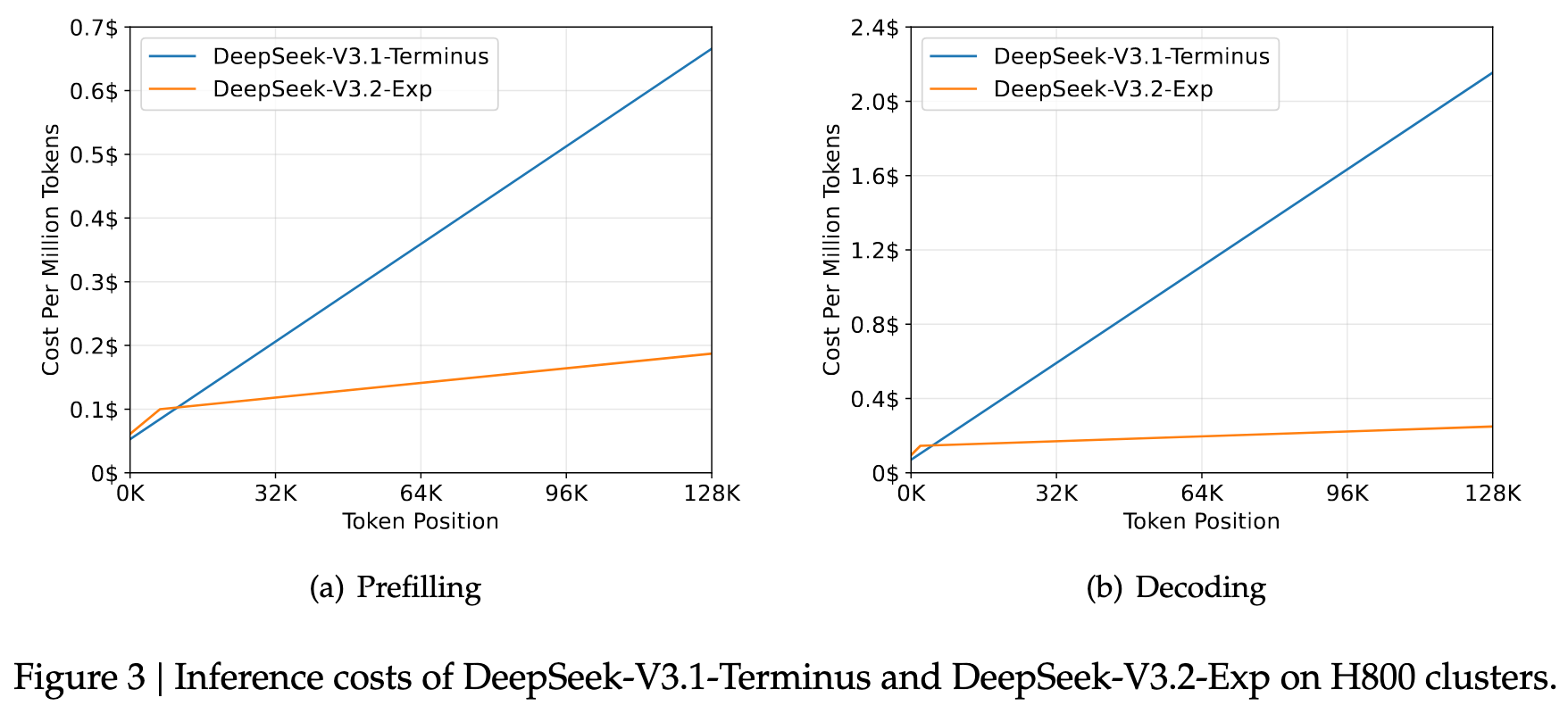
3.2 推理花费
4. 笔者总结
对于每个 token,只关注 sequence 中的 top k 个 token,而不是关注每个 token。感觉是符合直觉而且对于长文本能显著奖励计算复杂度的。
今天天气还不错。其中,错 的注意力和 今天 的关系并不大。








