
标题: Mixture of Lookup Experts[1]
FROM ICML 2025 oral arXiv GitHub
MoE 架构的模型在推理时只会激活部分专家,但是所有的专家都需要加载到内存中,导致了大量的显存展用。而如果只加载被激活的专家,则会增加推理时延。因此作者提出了 Mixture of Lookup Experts(MoLE)架构。
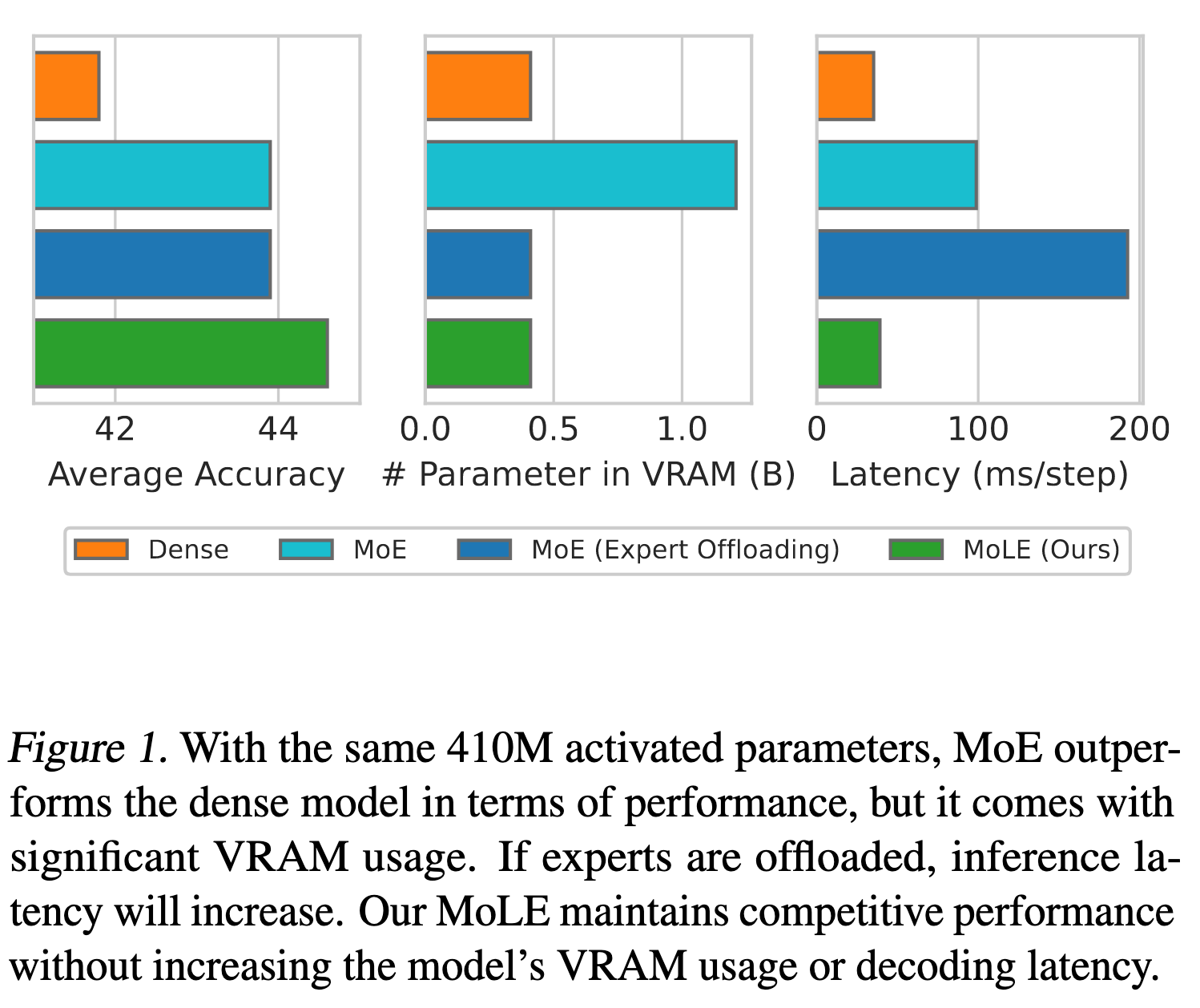
MoLE 在训练和推理中具有不同的结构。在训练过程中,MoLE 类似于 MoE,有一个路由器和若干个专家。与 MoE 中专家以中间特征为输入不同,MoLE 的专家以 Embedding tokens (即 Embedding 层的输出)为输入。并且,MoLE 在训练阶段激活所有的专家。
经过训练后,MoLE 不是直接用于推理,而是经过一系列的 re-parameterizations。 由于 Embedding 层的输出对于特定的 input ids 是固定的,因此专家的输入是个有限集,集合大小就等于词汇表大小。因此,对于 Embedding 层中的每个 token,预先计算所有专家对应的输出,创建替换原始专家的查找表 (LUTs, lookup tables)。 (但是这样就没有 attention 了,或者说只会 attention 自己🤔。而且即使在后面加一些网络层感觉也无济于事呀,因为这个就像把专家融入 Embedding 层一样,对 Embedding 层做了个非线性变换。何况作者还没加额外的网络层。)
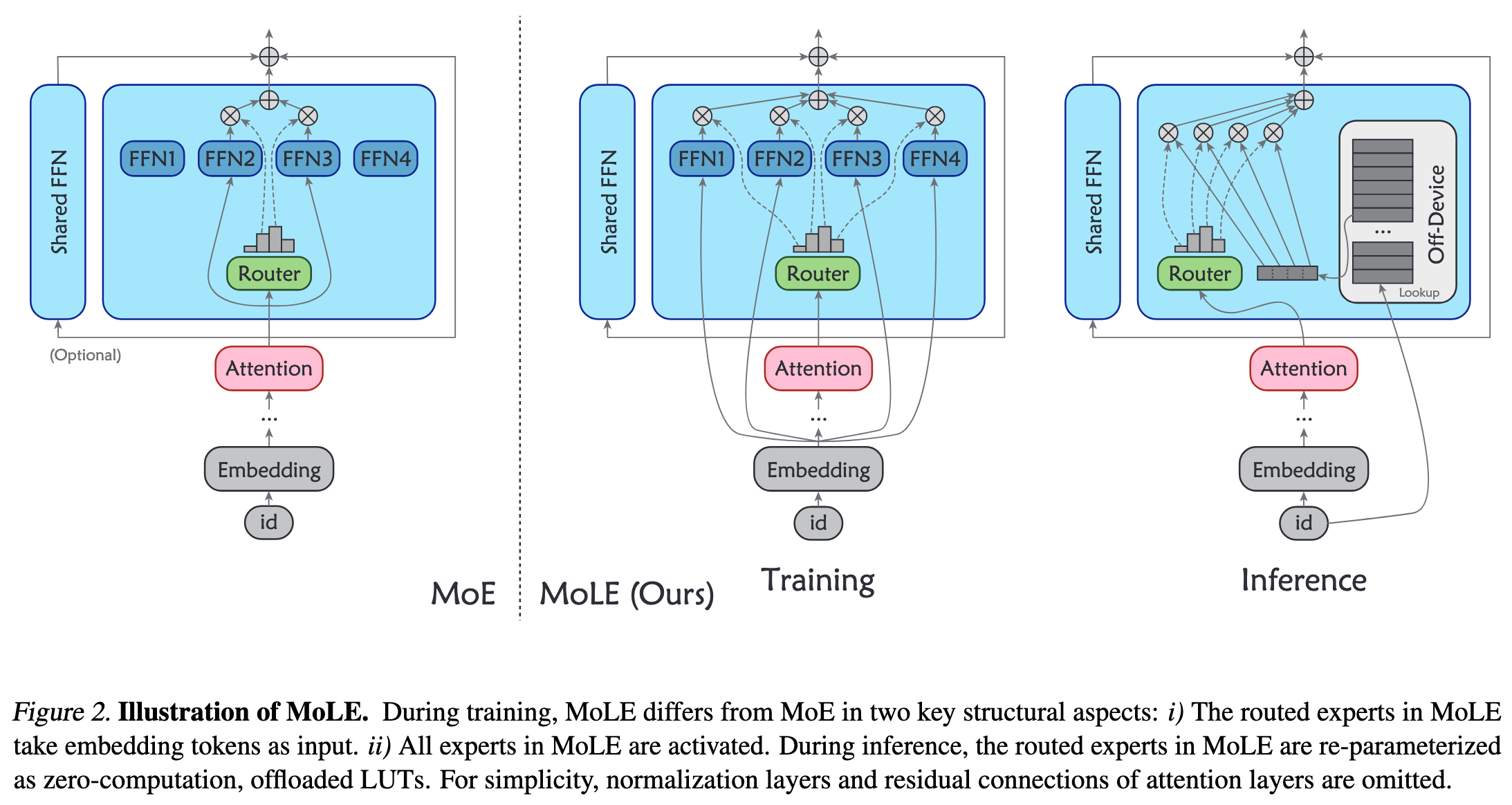
1. 训练阶段
MoE 专家的计算公式
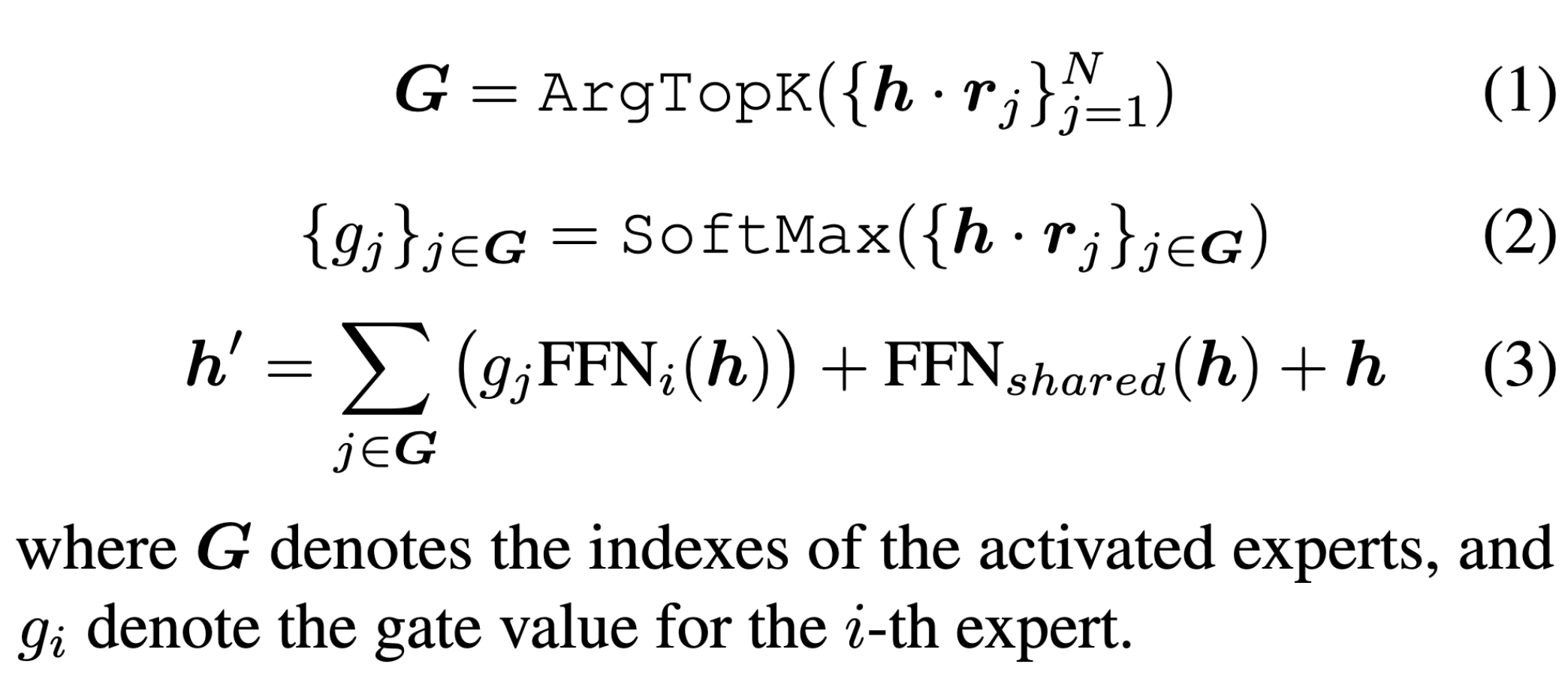
MoLE 专家的计算公式
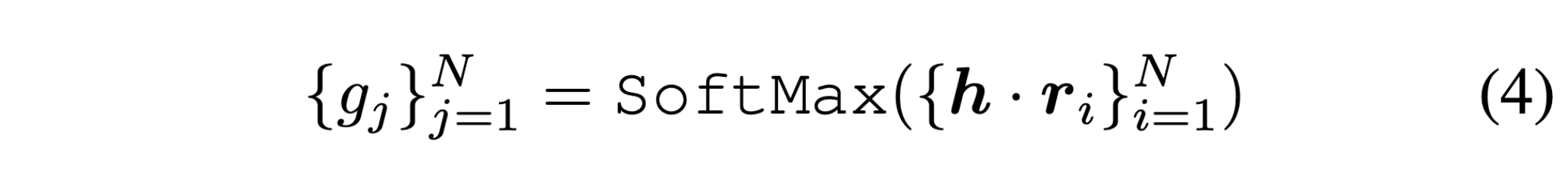
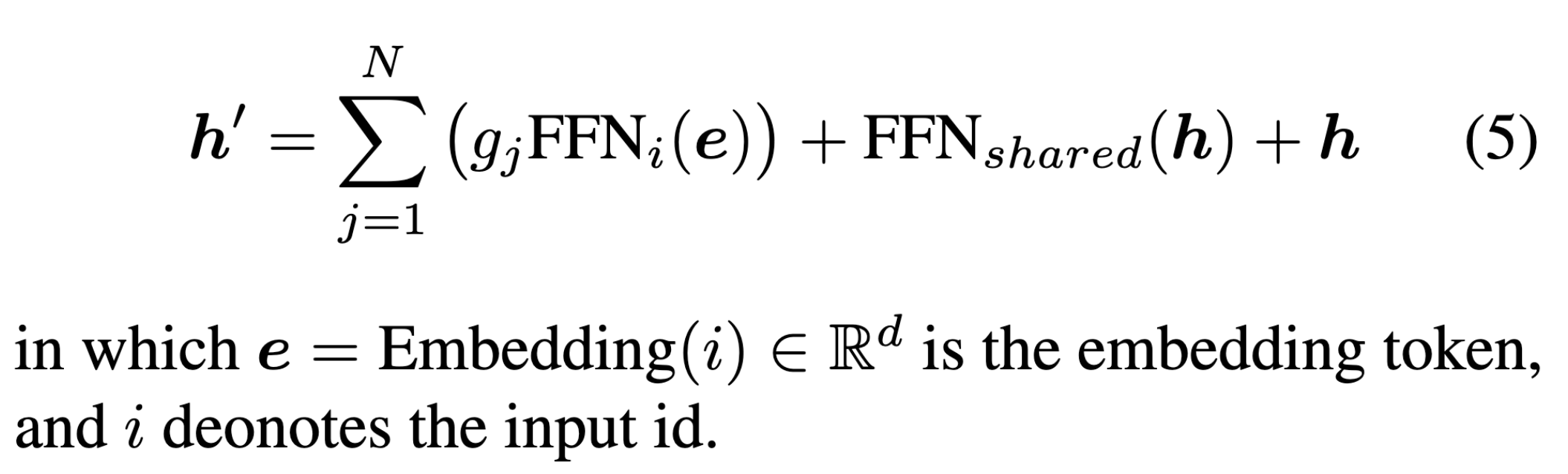
训练时激活所有的专家,所以不需要考虑专家复杂均衡。使用交叉熵损失函数进行训练。
2. 推理阶段
预先计算每个专家的输出。因为输出是个有限集,所以可以提前计算,然后将其存储在查找表中。在推理时,只需根据输入的 token 查找对应的专家输出,而无需重新计算。这大大加快了推理速度,并减少了显存占用。

然后,专家的计算就变成了
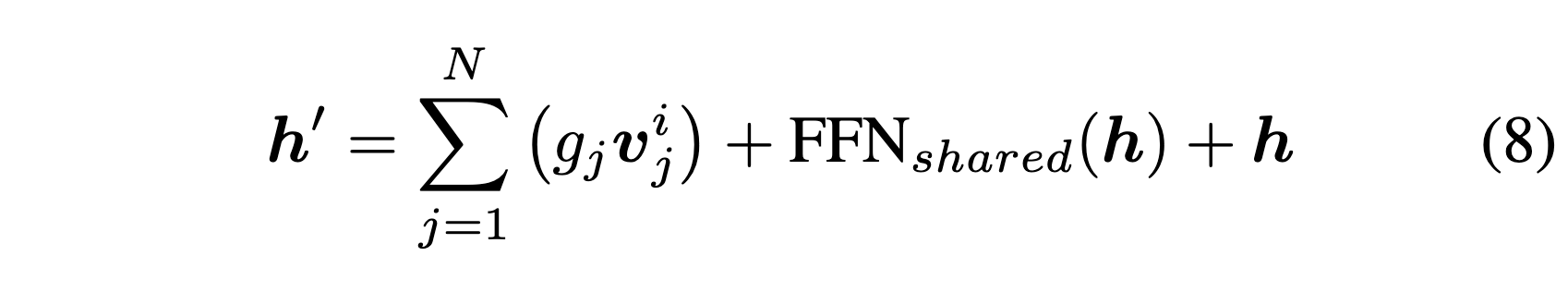
这就是 MoLE 的整个过程。。。然后关于 attention 的问题作者的回答是这样的。

感觉好牵强😷
3. 复杂性分析

其中, 表示被路由到的专家的维度, 表示共享专家的维度, 激活专家的数量。(广义的,严格上是激活专家的数量减去共享专家的数量)
4. 实验
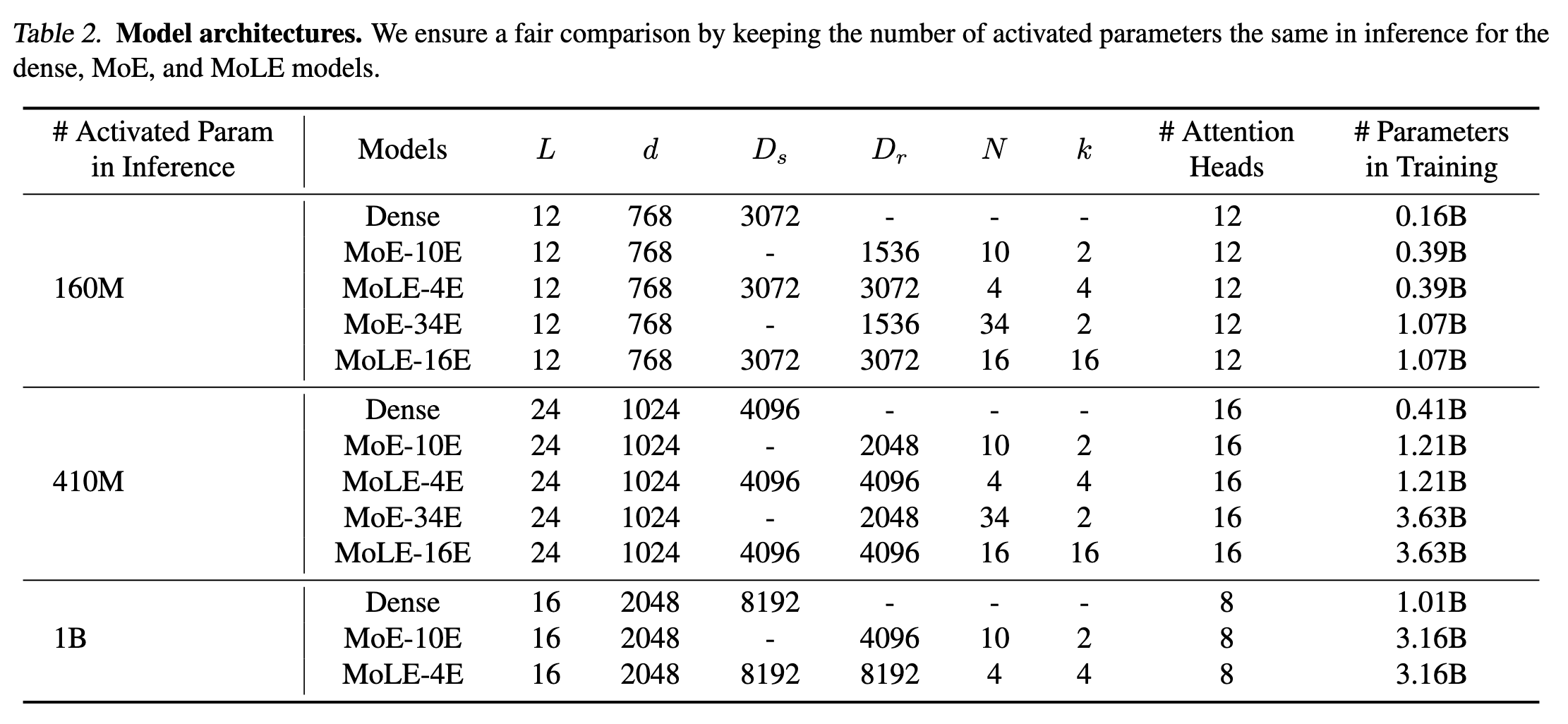
作者对比了这几个参数量的模型
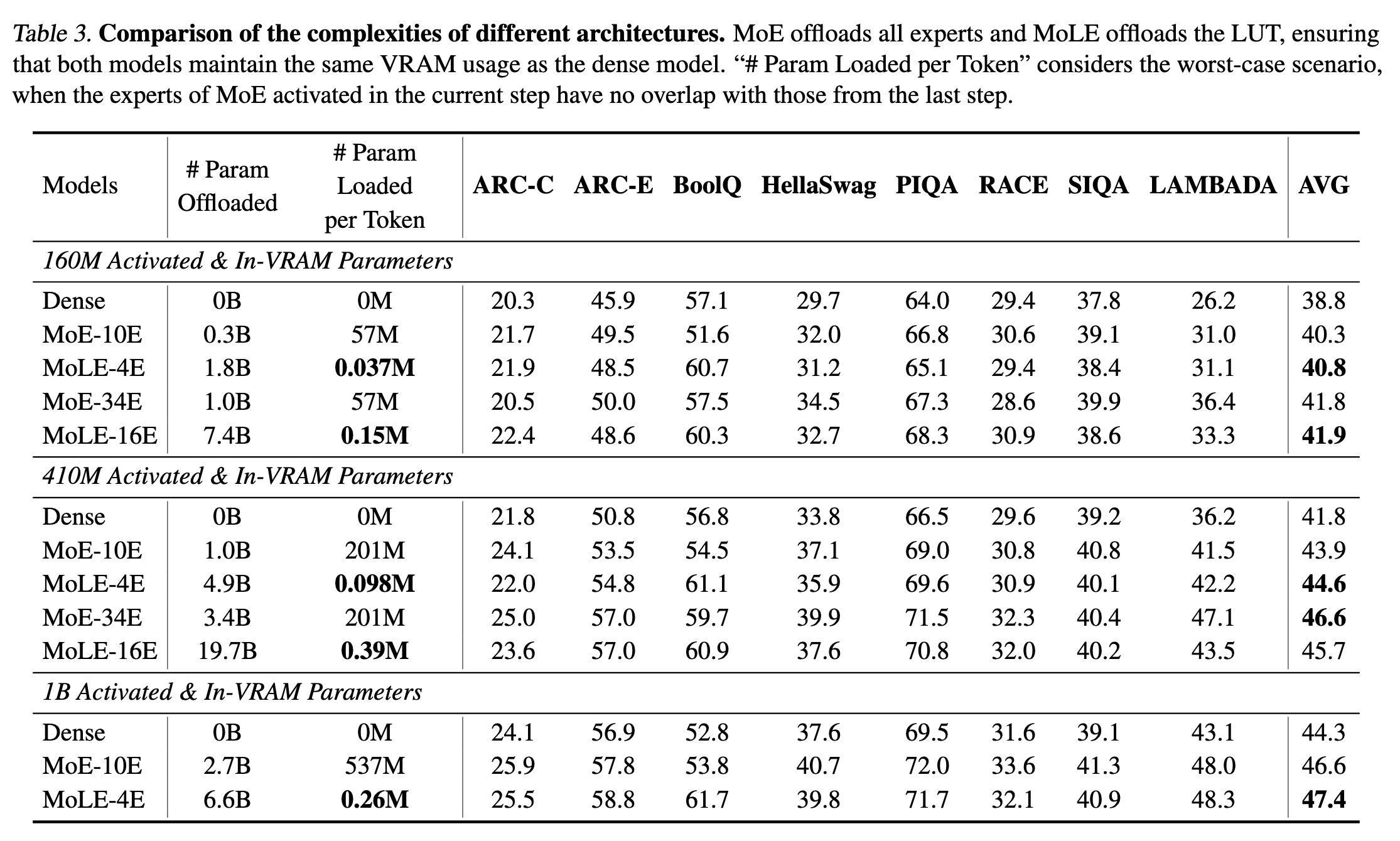
5. 实验结果

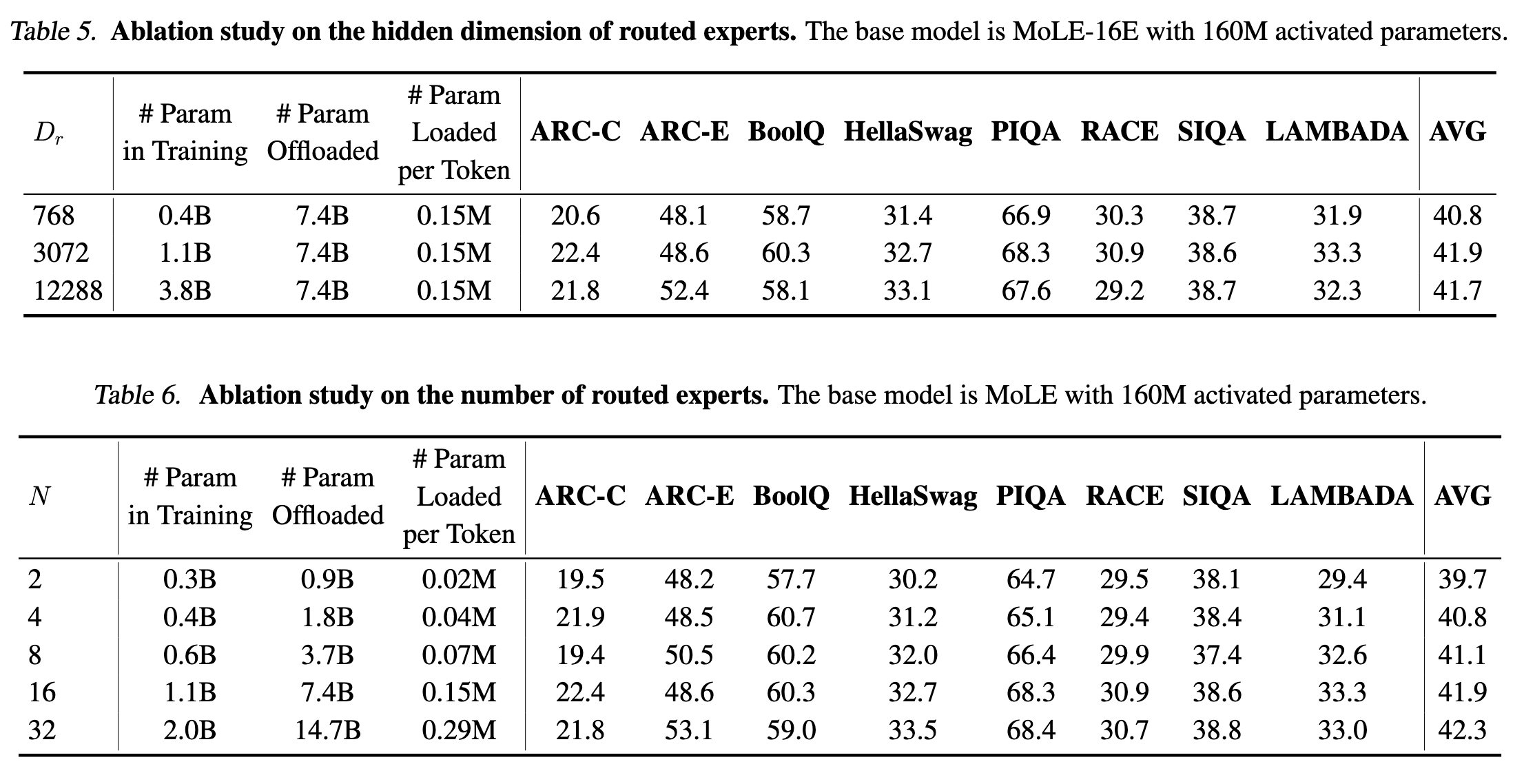
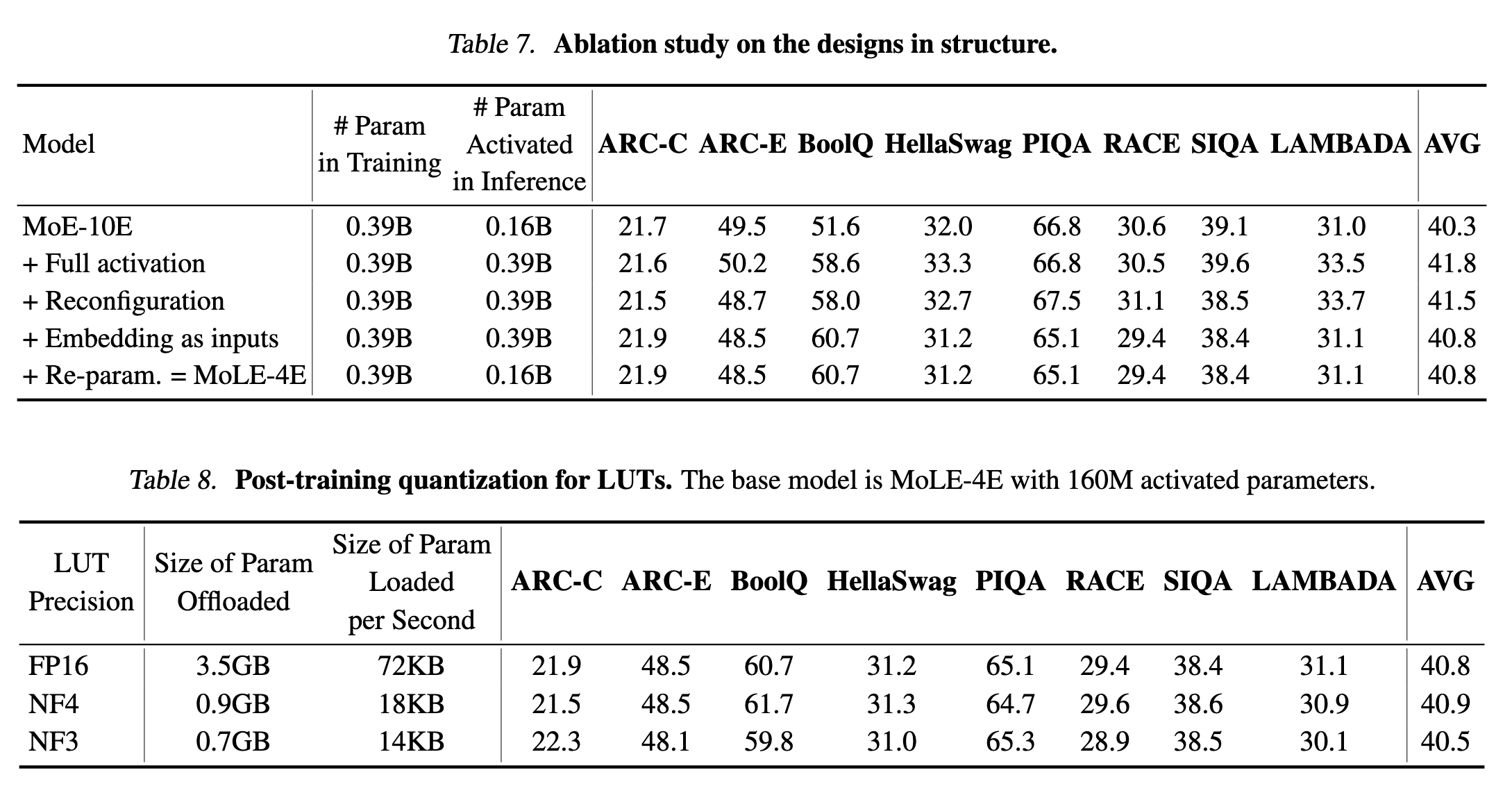
6. 笔者总结
用 Embedding 层的输出作为专家的输入,感觉这就是一个 Embedding 层的非线形变换呀。退一步讲,如果我在图 2. 抛弃专家是不是也是可以的呢。
review: hear
References
注:若本文中存在错误或不妥之处,欢迎批评指正。








