
标题: Forest-of-Thought: Scaling Test-Time Compute for Enhancing LLM Reasoning[1]
FROM ICML 2025 华为诺亚方舟实验室 arXiv GitHub
作者提出了 FoT(Forest-of-Thought)推理框架,特点:
-
利用多个 ToT 进行集体决策,提升推理能力。 -
采用稀疏激活策略,选择最相关的推理路径,提高效率和准确性。 -
引入动态自纠正策略,实现实时纠错并从过去的错误中学习。 -
采用共识引导的决策策略,优化正确性和计算资源。
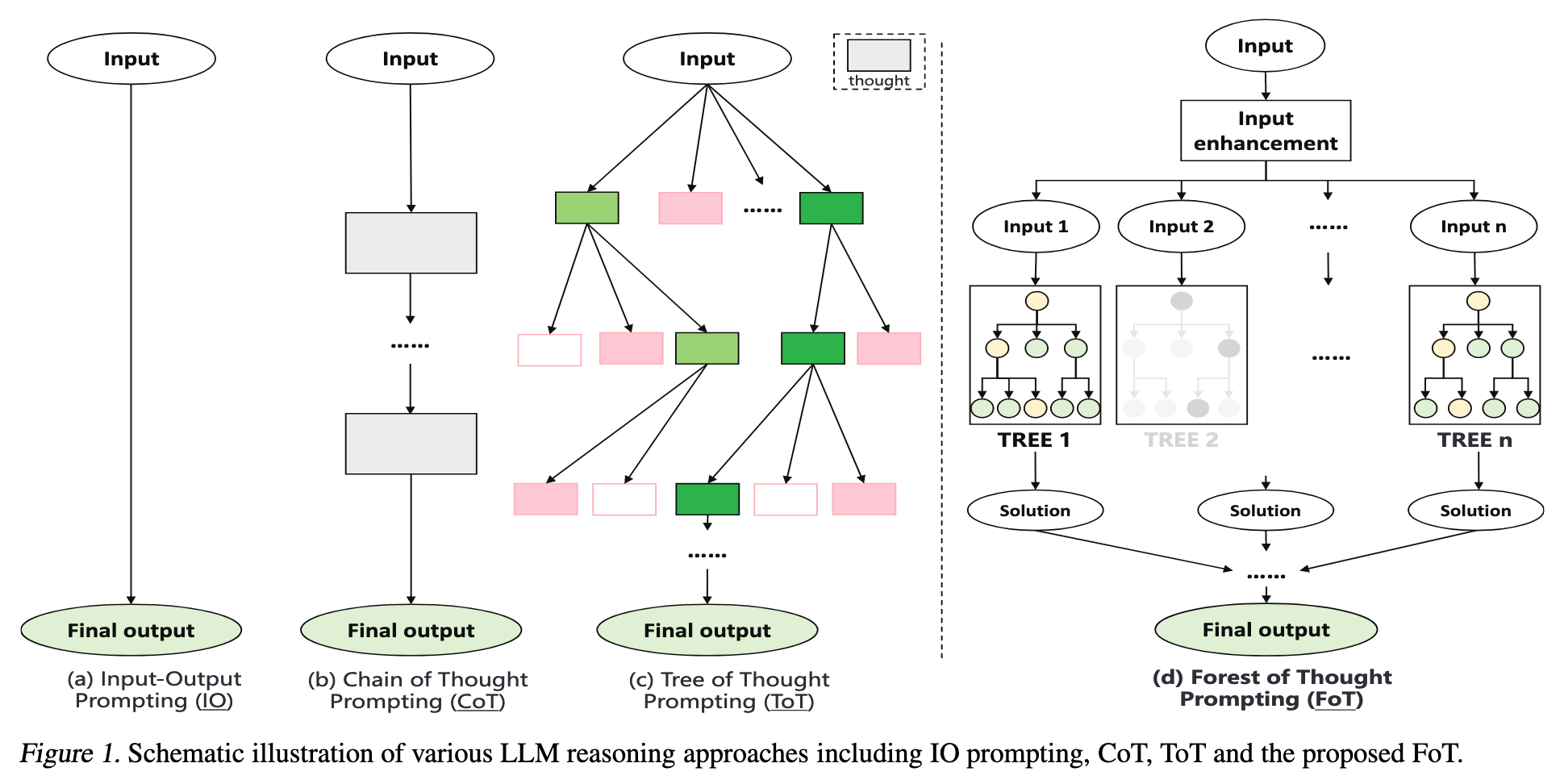
1. XoT 缺点
-
CoT (Chain-of-Thought):对于复杂的数学和逻辑推理任务,需要多维度考虑,CoT 的线性特点很难胜任。 -
ToT (Tree-of-Thought):复杂任务的搜索空间会非常大,ToT 的树形结构可能导致计算资源的浪费和效率的降低。
2. FoT
2.1 Sparse Activation
只计算哪些最相关的推理树。在每个推理树中,只会利用每层的 top-m 的节点进行计算。如果某个节点无法生成有效的输出,则会被终止。表示为
\(\mathcal{A}_{i,l} = \{ k \mid s_{i,l,k} \text{ is in the top } m \text{ at layer } l \}\)
其中
-
\(\mathcal{A}_{i,l}\):树 \(T_i\) 在第 \(l\) 层被激活节点的集合 -
\(i\):树的索引,用于区分不同的树 \(T_i\) -
\(l\):层索引,表明是树 \(T_i\) 的第几层 -
\(k\):节点编号,用来区分树 \(T_i\) 第 \(l\) 层中的不同节点 -
\(s_{i,l,k}\):树 \(T_i\) 第 \(l\) 层节点 \(k\) 的激活分数 -
\(m\):设定的阈值,即某层节点得分排前 \(m\) 名的节点会被判定为“激活”状态
最终模型的输出可以表示为
2.2 Input Data Augmentation
知识库 \(\mathcal{B}\) 中检索背景信息和先验知识。然后和原始输入拼接到一起作为输入。
其中
-
\(Sim(\cdot)\):用于计算两个向量余弦相似度的函数 -
\(\text{TF}(\cdot)\):对文本进行 TF-IDF 变换的操作,能将文本转化为对应向量表示。类似于 embedding -
\(\oplus\):文本字符串拼接操作,将 \(x\) 和 \(\mathcal{B}_{i_{max}}\) 对应的文本内容拼接在一起 。
这不就是一个 rag 吗🥲
2.3 Dynamic Self-Correction Strategy
对于来自推理树的初始结果 \(s_i\),自纠正策略评估其正确性和有效性,并在每个推理步骤完成后分配相应的分数。分数可以通过 LLM \(p_\theta\) 获得:
\(score_i \sim p_\theta(score_i | s_i, x)\)
分数低于预定义阈值会自动触发修正机制。该机制首先回顾和分析过去的失败案例(表示为 \(\mathcal{C}\)),以识别低分的原因和常见的错误模式,随后尝试纠正错误并优化推理方向。校正过程可以由 LLM 本身执行:
\(s_i’\sim p_{{\theta}_1}(s_i’ | \mathcal{C}, s_i, x)\)
对于数学任务,额外采用了一种基于规则的矫正方法。即
\(s_i’ = F(s_i)\)
就是判断一些常见的错误,比如分母为 0
最终伪代码如下:

感觉这一步就是用另外一个模型对每次推理结果进行一个打分。相当于一个纠正错误的功能。但是为什么叫自纠正策略呢。而且这样不会导致推理速度下降吗
2.4 Decision Making Strategy
为了解决复杂的数学问题,作者设计了共识引导的专家决策(CGED, Consensus-Guided Expert Decision)策略。
选择最佳叶节点: 在 FoT 方法中,每个独立树通过其独特的推理路径生成一个或多个可能的答案。子树投票选出获得最多支持的候选答案。如果无法达成共识,数学专家会评估推理过程并选择最终答案,以确保其准确性和有效性。
FoT 决策过程: 在推理过程中,每棵激活的树都会为其路径生成最优解。然后通过多数投票和专家评估过滤这些答案。如果多个树的结果有冲突,则专家决定最终答案。
总结一句话就是,有多数选多数,都冲突的话就让专家决定。
最终的 FoT 伪代码如下

3. 实验
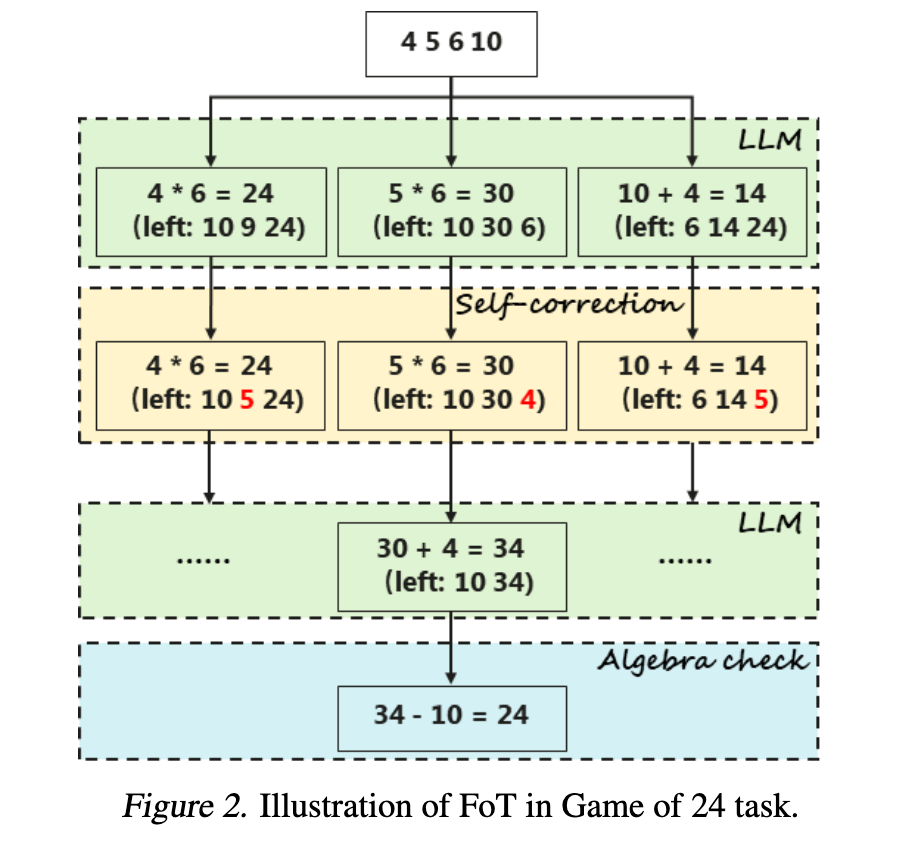
3.1 24 点游戏
推理过程
推理时间
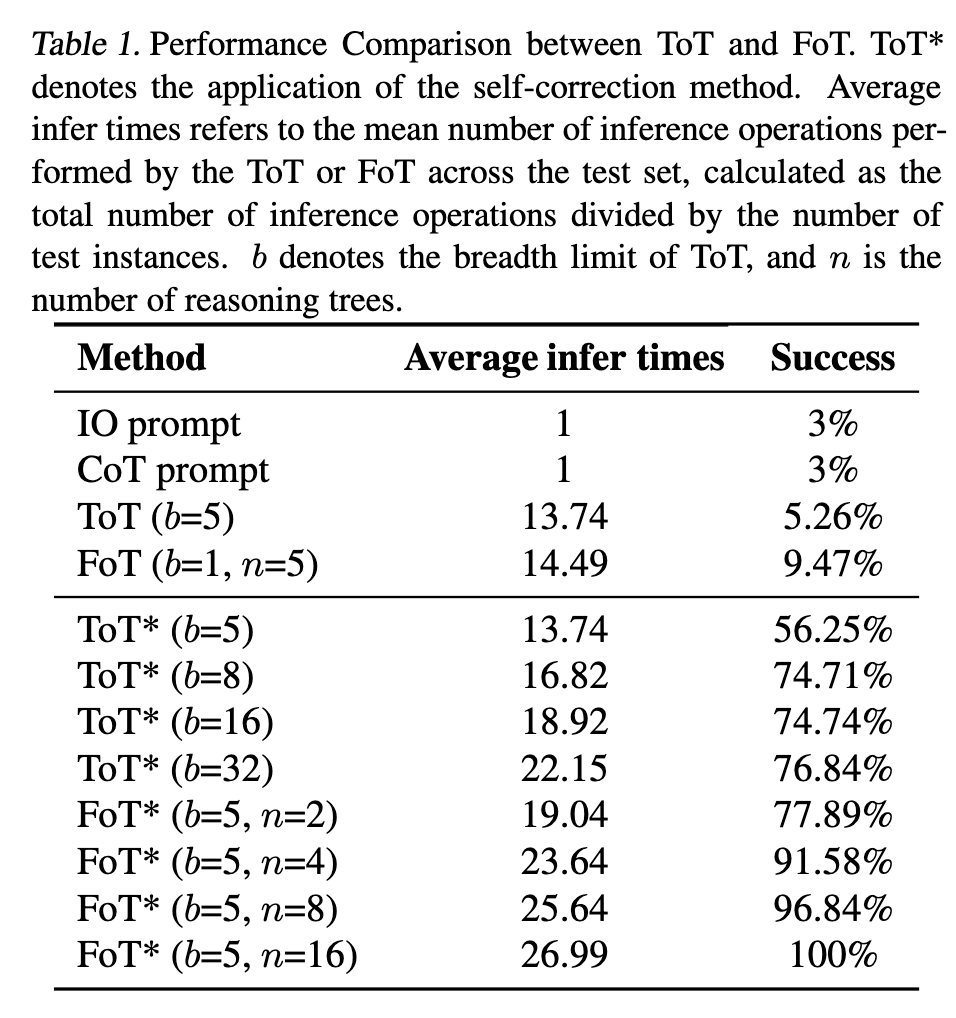
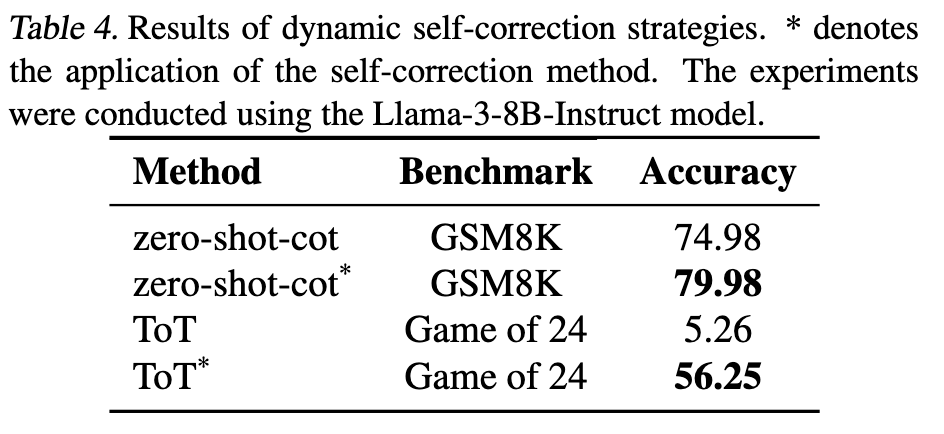
可以看到,推理时间确实会变长一点,但是也在可接受的范围内。不够,结合自纠正的 ToT 为什么推理时间没变呢?
3.2 GSM8K
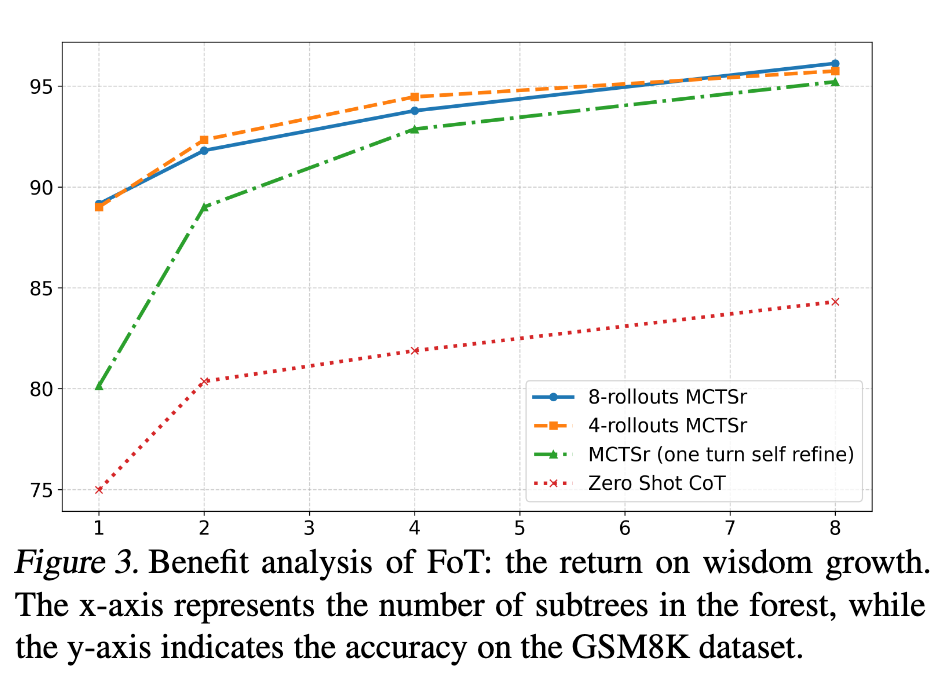
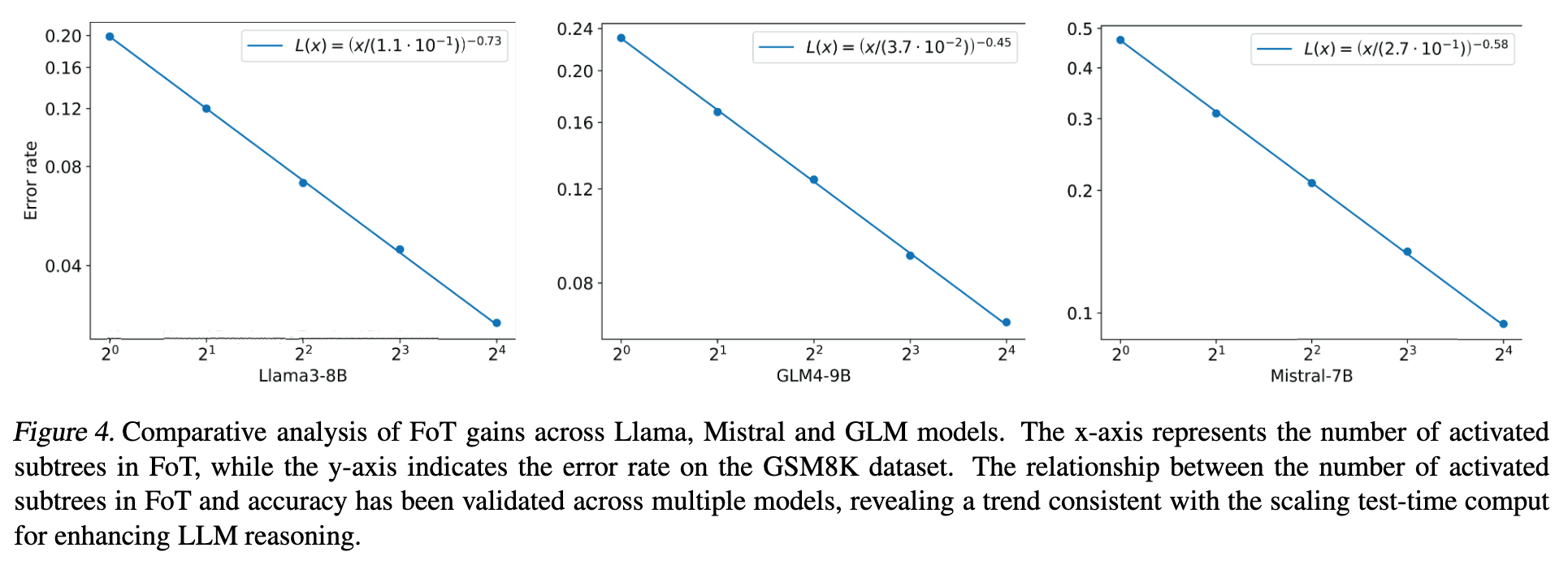
3.3 MATH
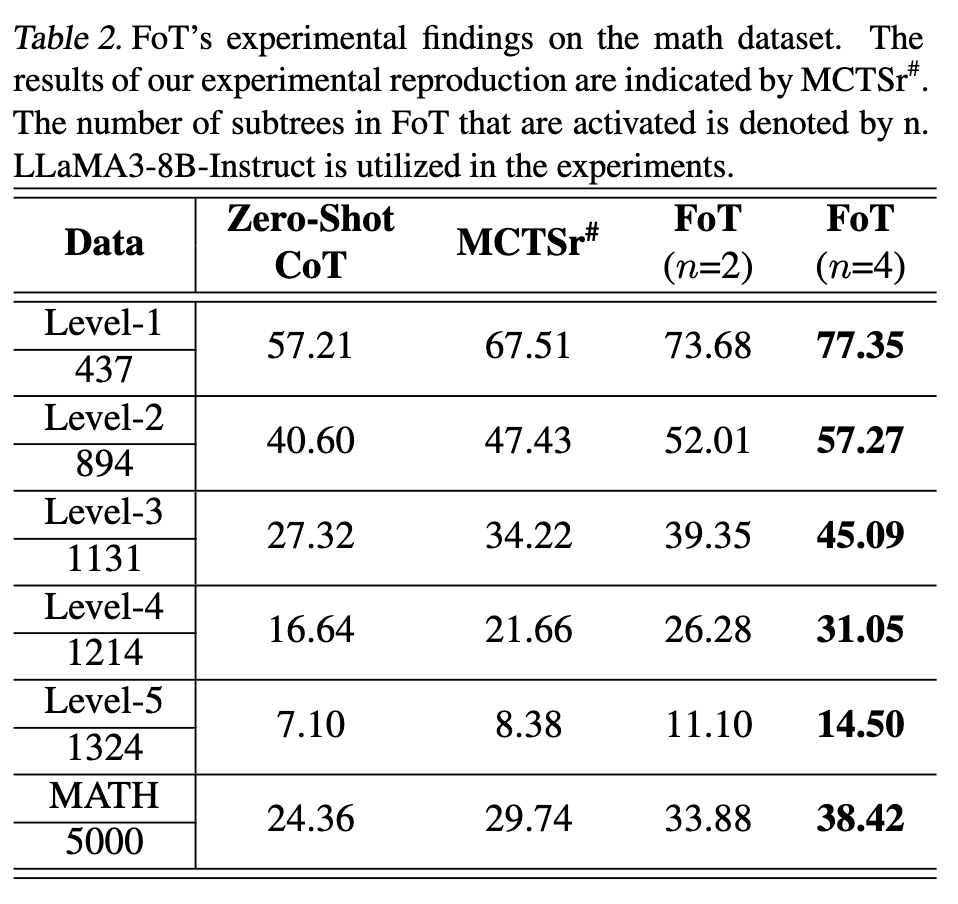
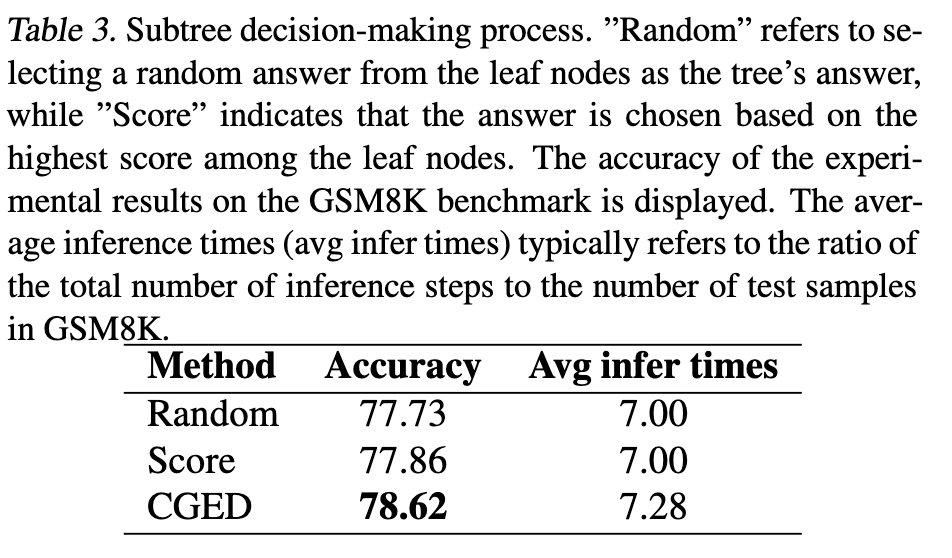
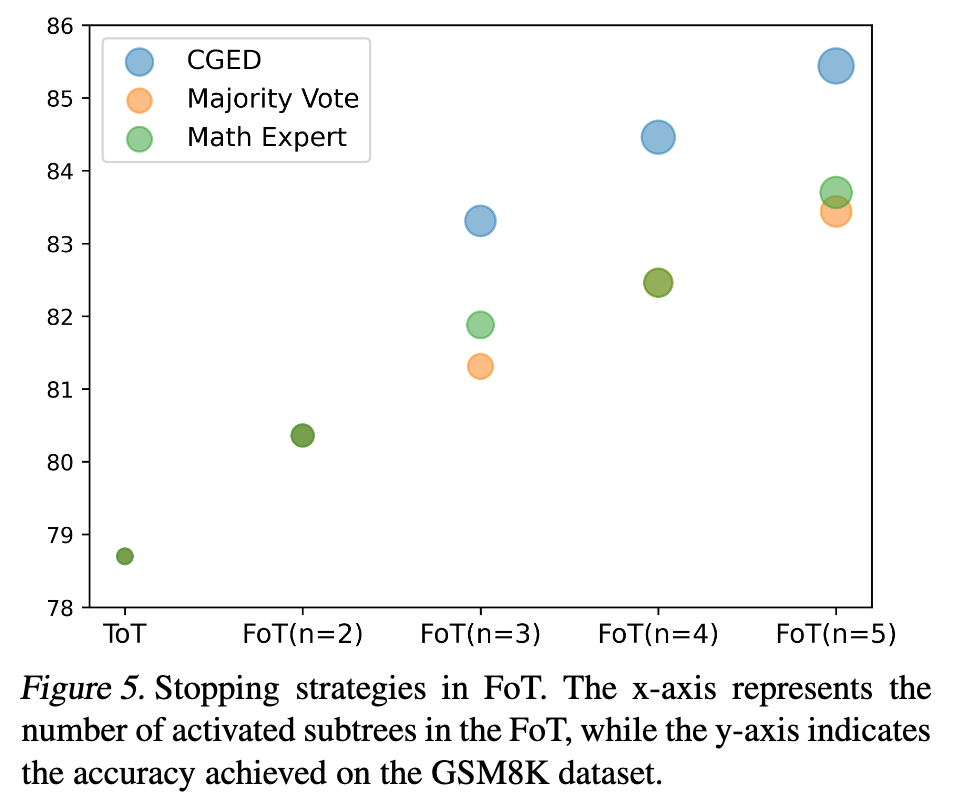
3.4 消融实验
4. 笔者总结
-
结合多个 ToT 进行集体决策,提升推理能力。同时利用 Sparse Activation 策略,减少计算资源的浪费。但是作者并没有提到每个节点的 score 是如何计算的。 -
输入数据增强,感觉就是一个 rag 系统,检索背景知识和先验。这种放到 CoT 中不也是一样的吗。实验并没有提到其他方法是否使用 rag,不知道公不公平。 -
自纠正和 CGED 感觉就是通过 LLM 来进行打分和决策。相当于用时间换精度。但奇怪的是,结合自纠正的 ToT 推理时间并没有增加。 -
感觉这篇论文的工程性比较强。
Reviewer: hear
References:
注:若本文中存在错误或不妥之处,欢迎批评指正。