
标题: Demystifying Long Chain-of-Thought Reasoning in LLMs[1]
目前 long CoT 广泛应用于各种 LLMs 中,但其中机制尚不清楚。所以作者系统的研究了 long CoT 推理的机制,欲找出模型生成 long CoT trajectories 的关键因素。通过广泛的 SFT 和 RL 实验,作者提出了 4 个主要的发现:
- 虽然 SFT 不是必要的,但它简化了训练并提高了效率。
- 推理能力通常会随着训练计算量的增加而逐渐显现,但这种发展并非必然。因此,reward shaping 对于 CoT 长度增长的稳定性至关重要。
- 扩展可验证的奖励信号是强化学习的关键。研究发现,对从网络中提取的含噪声解决方案加以过滤机制处理后加以利用,在这方面展现出强劲潜力,尤其适用于 STEM 推理等分布外(OOD, out-of-distribution)任务。
- 纠错等核心能力是基础模型与生俱来的 “潜质”,但要通过强化学习在复杂任务中充分激活这些能力,需要大量计算资源作为支撑。更重要的是,由于这些能力的显现往往是渐进且多维度的,衡量其发展程度必须采用精细、全面的评估方法,避免单一指标造成的误判。
1. 使用 Long CoT 和 Short CoT 数据进行 SFT 的对比
1.1 Long CoT 数据获取
作者对比了两种数据获取方法
- 通过提示 Short CoT 模型(Qwen2.5-72B-Instruct)生成原始动作并按顺序组合,构建 Long CoT trajectories;
- 从表现出涌现的 Long CoT 模式的现有 Long CoT 模型(QwQ-32-Preview)中蒸馏出 Long CoT trajectories;
结果如下图,很明显方法 2 更好。
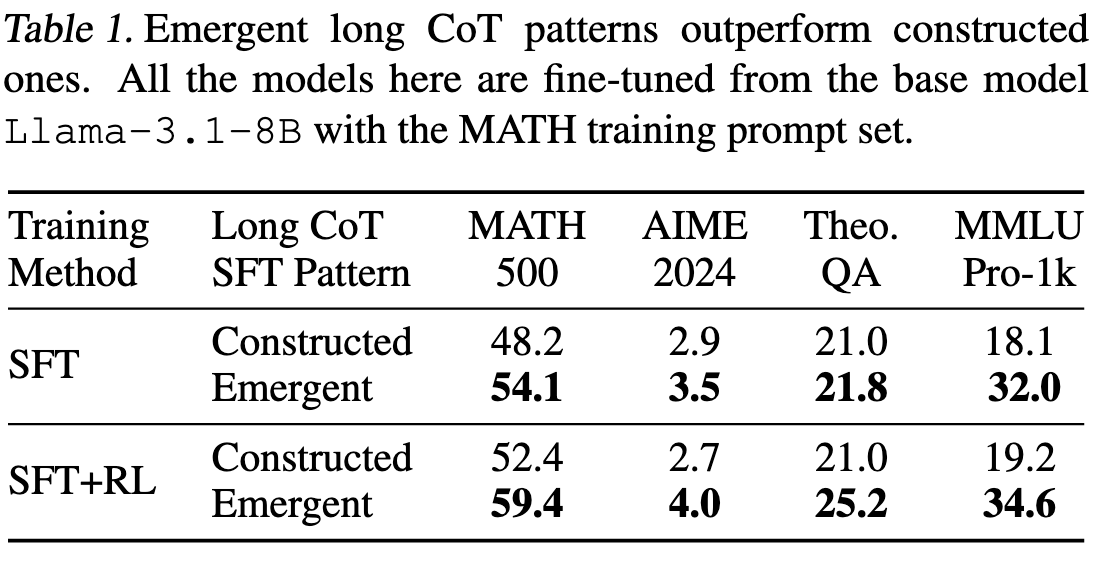
1.2 Short CoT 数据获取
从 Qwen2.5-Math-72B-Instruct 进行蒸馏。
1.3 对比结果
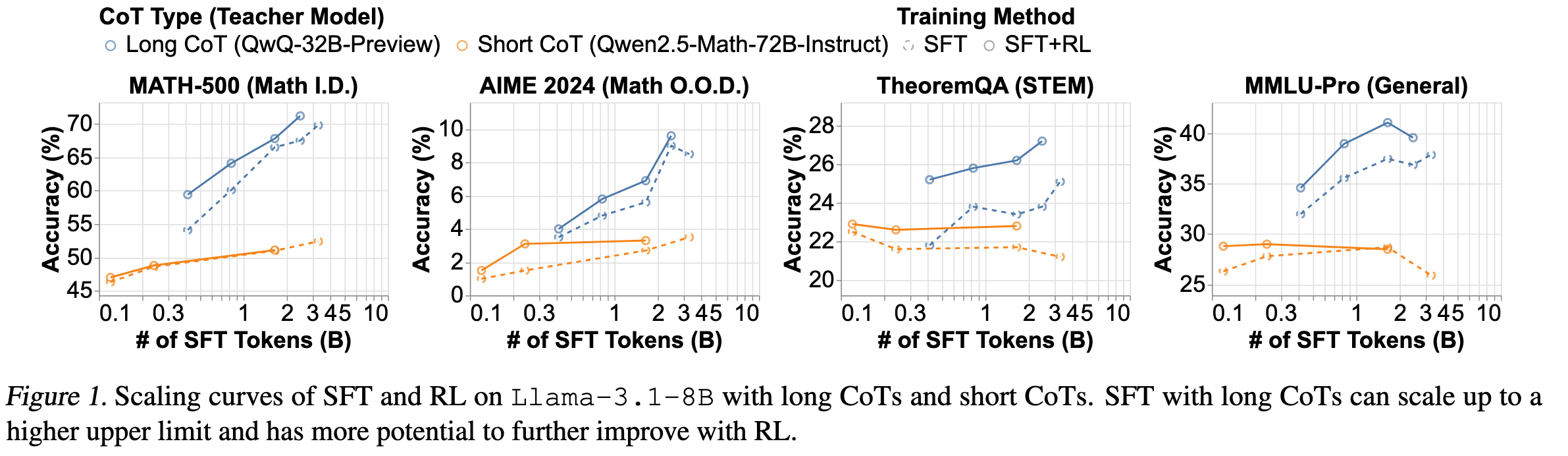
可以看到,Long CoT 的效果明显比 Short CoT 好。 Long CoT 时:SFT + RL 的效果比单纯 SFT 更好。 Short CoT 时:SFT + RL 的效果普遍比单纯 SFT 更好,但在 Math 任务上好像单纯做 SFT 效果更好。这也说明了 Long CoT 更容易提升 RL 效果。
2. 奖励函数对 CoT 长度和模型表现的影响
2.1 Classic Reward
使用 QwQ-32B-Preview 蒸馏 Llama3.1-8B 和 Qwen2.5-Math-7B。采用基于规则的奖励函数,正确答案奖励 1(Classic Reward)。
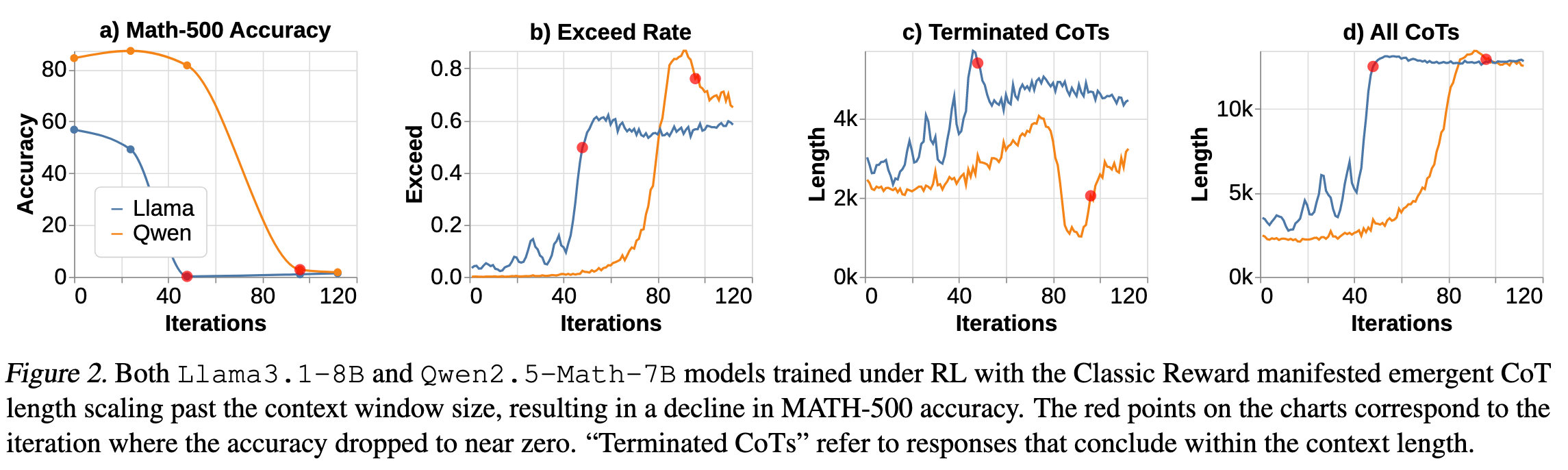
两种模型在训练过程中都增加了 CoT 长度,最终达到了上下文窗口限制。由于 CoT 超过窗口大小,这导致训练准确性下降。此外,不同的 base model 表现出不同的缩放行为。与Qwen-2.5-Math-7B 相比,较弱的 Llama-3.1-8B 模型显示出更大的 CoT 长度波动。
同时,CoTs Exceed Rate 在达到低于 1 的某个阈值时趋于平稳。这表明上下文窗口大小对 CoT 长度惩罚具有隐式的作用。即使奖励函数没有引入对上下文长度的惩罚。
2.2 Cosine Reward
作者设计了一个奖励函数,使用 CoT 长度作为额外的输入,并观察一些排序约束。首先,正确的 CoT 比错误的 CoT 获得更高的奖励。其次,更短的正确 CoT 比更长的正确 CoT 获得更高的奖励,这激励模型更有效地使用推理计算。第三,较短的错误 CoT 应比较长的错误 CoT 受到更高的惩罚。这促使模型在较少可能得到正确答案的情况下延长其思考时间。
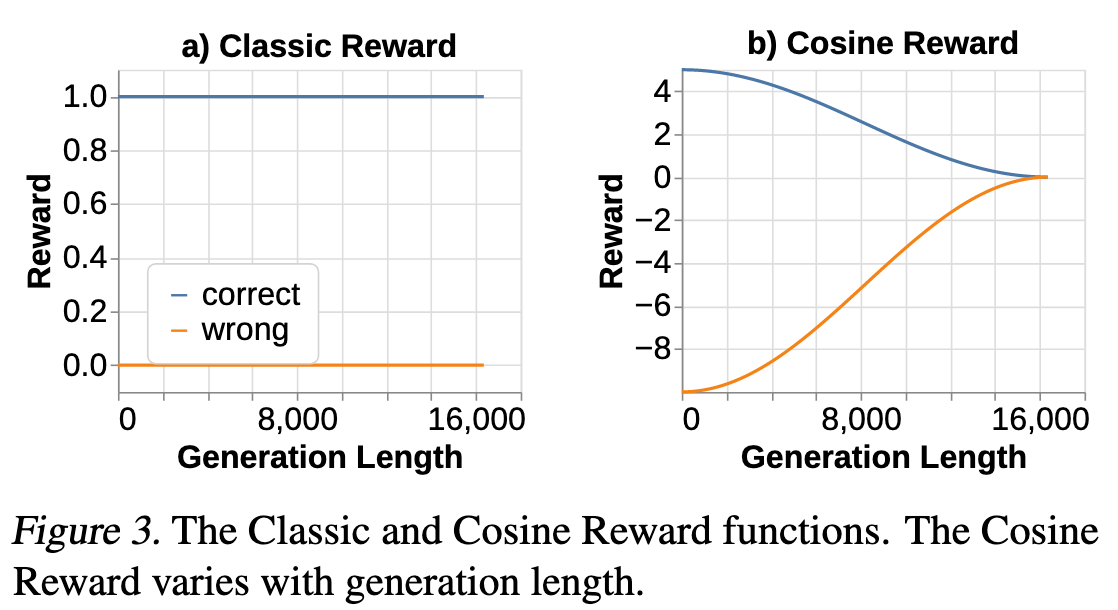
作者发现使用分段余弦函数很方便,它易于调整和平滑。作者将此奖励函数称为余弦奖励(Cosine Reward),如图 3 所示。这是一个稀疏的奖励,仅在 CoT 结束时根据答案的正确性发放一次。公式如下:

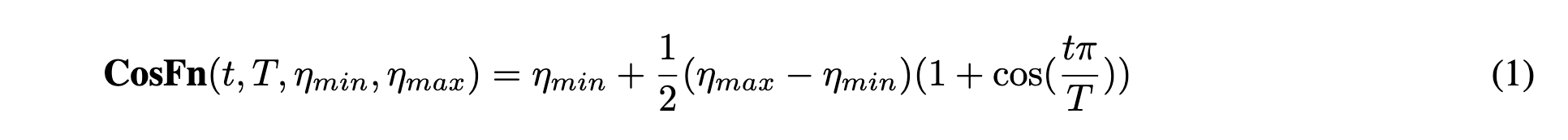
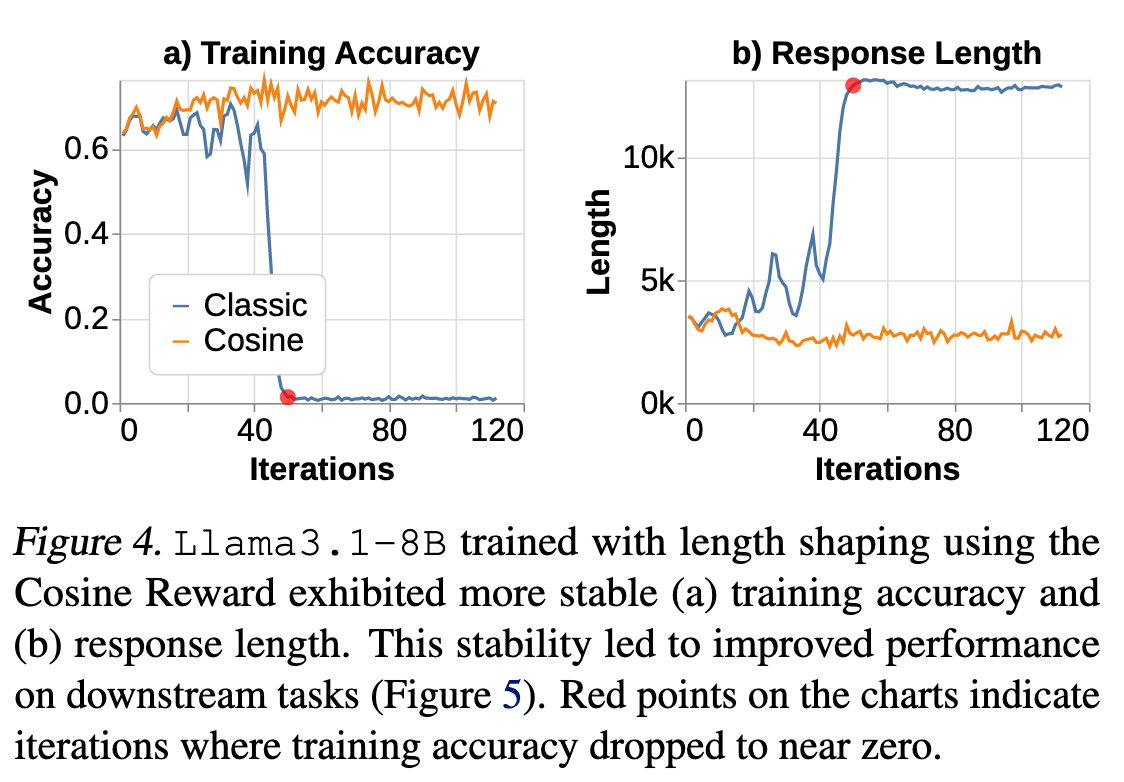
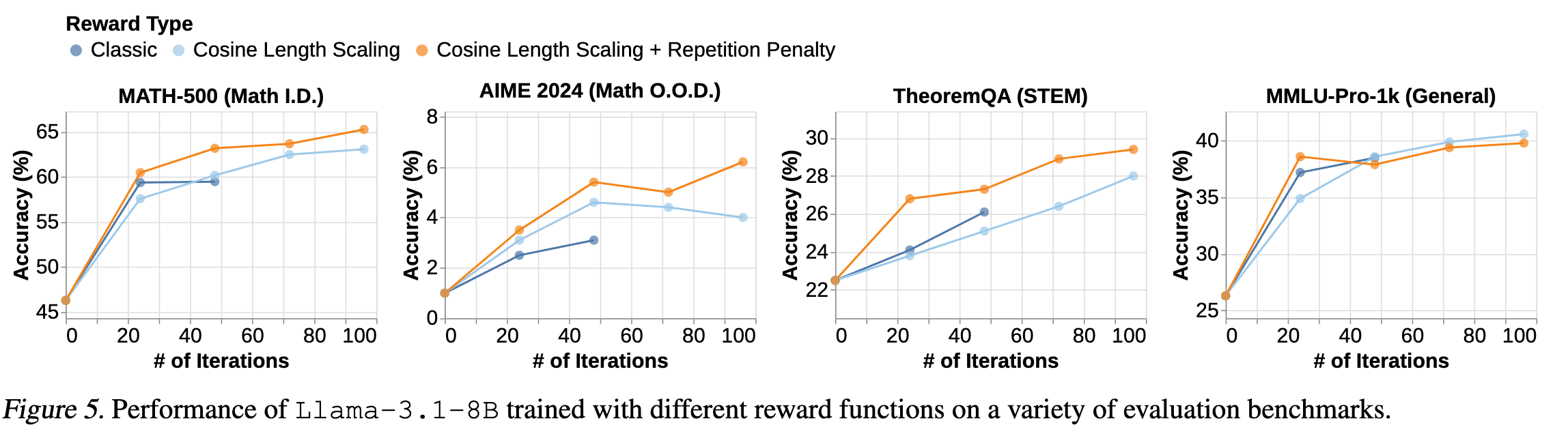
用 QwQ-32B-Preview 蒸馏 Llama3.1-8B,结果表明 Reward shaping 可用于稳定和控制 CoT 长度,同时提高准确性。
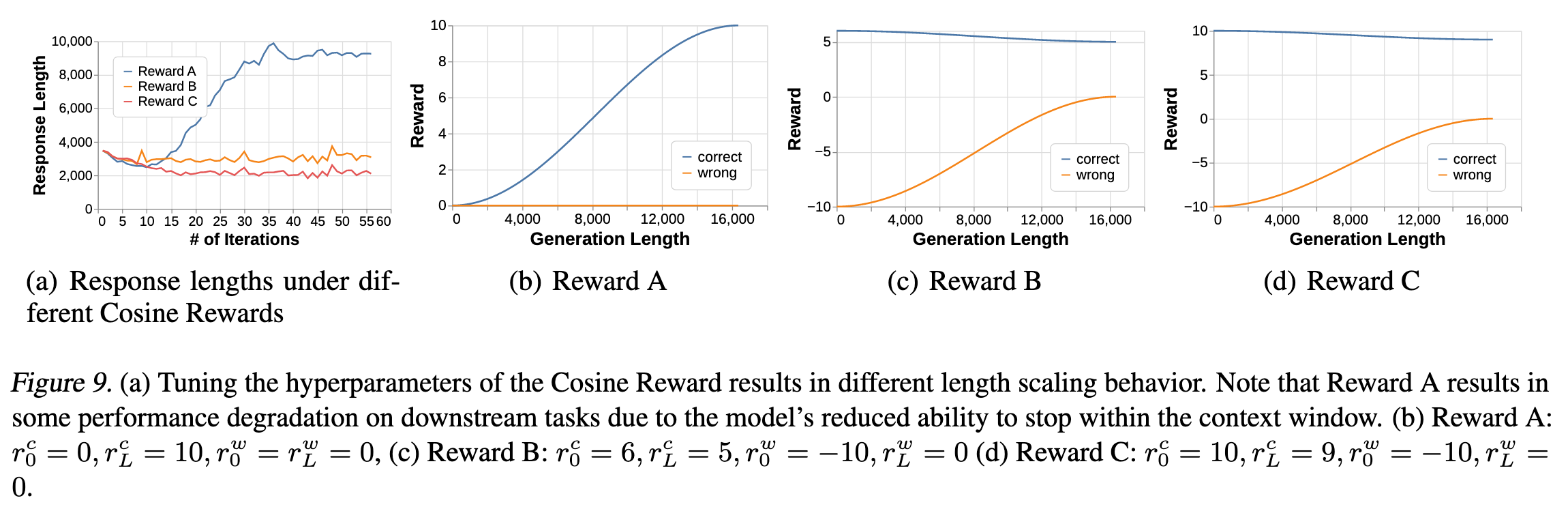
关于超参数设置如图 9 所示。如果正确答案的奖励随着 CoT 长度的增加而增加(),则 CoT 长度呈爆炸性增加。并且,相对于错误奖励,正确的奖励越低,CoT 长度就越长。作者将其解释为一种训练有素的风险规避,其中正确和错误奖励的比率决定了模型对答案的置信度,根据置信度用答案终止 CoT ,来获得正期望值。
3. 上下文长度
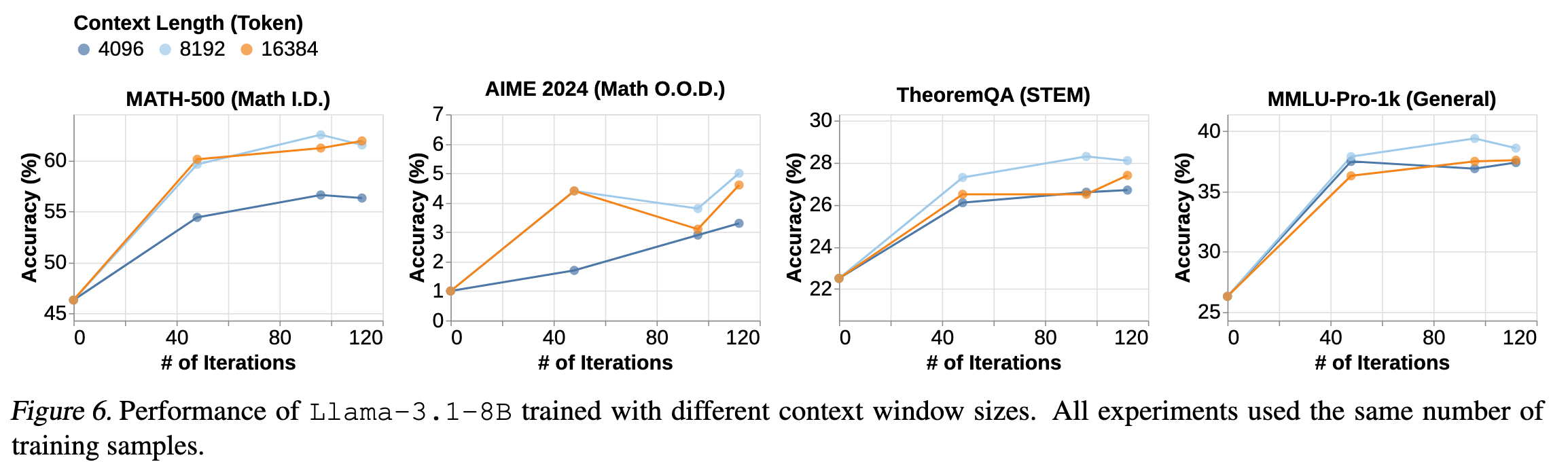
作者对 4K 8K 16K 上下文长度进行了实验。发现 8K 效果比 4K 好。但是 16K 需要更多的训练,表现才会超过 8 K,因为模型需要更多的训练才能充分利用更长的上下文长度。
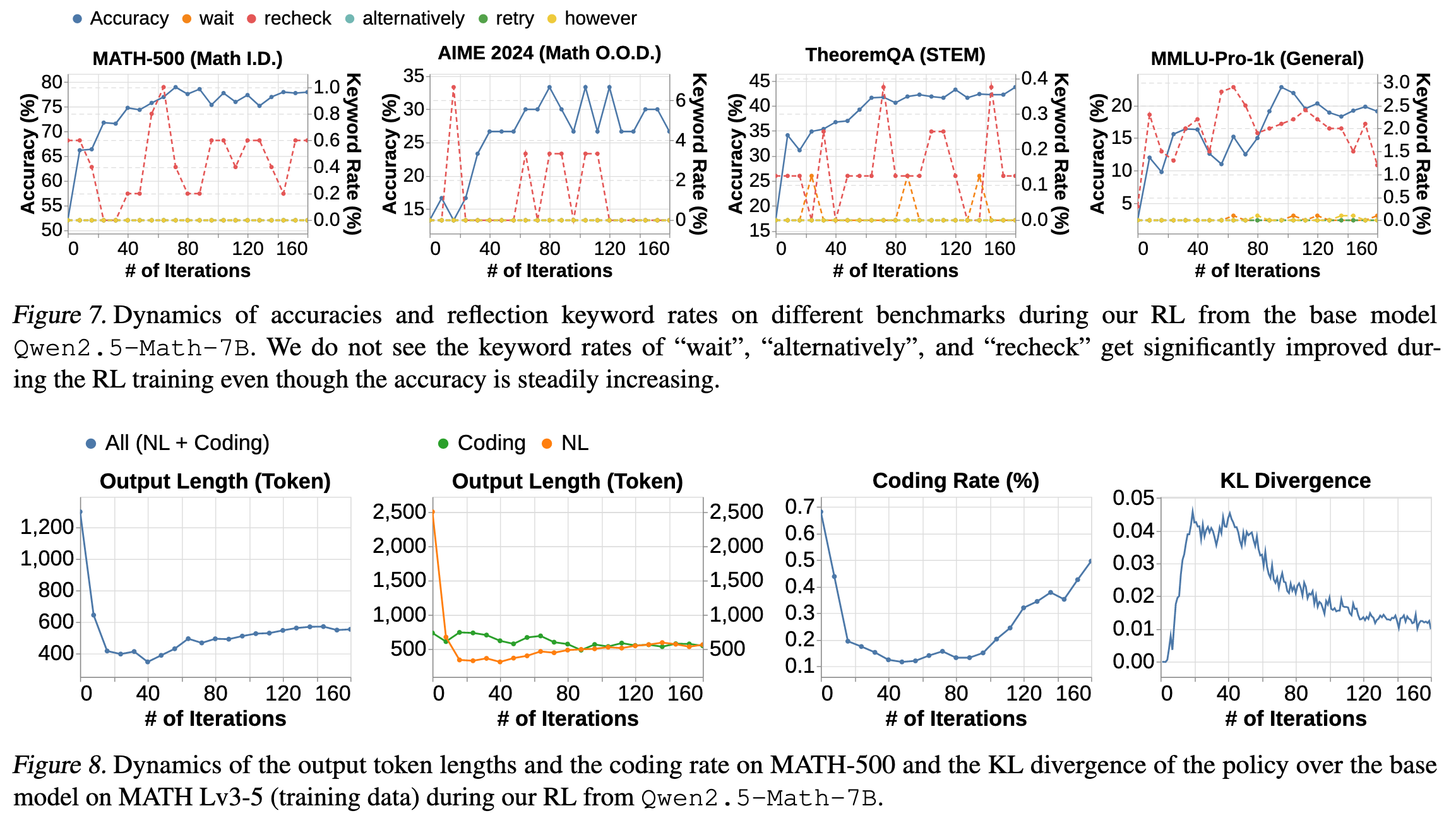
作者观察到,随着训练的进行,会出现 Length reward hacking 的现象。模型会生成重复的 CoT,而不是有助于解决问题的 CoT。并且模型的解决方案会变少。作者通过统计 CoT 中的 alternatively 词频来量化这一现象。
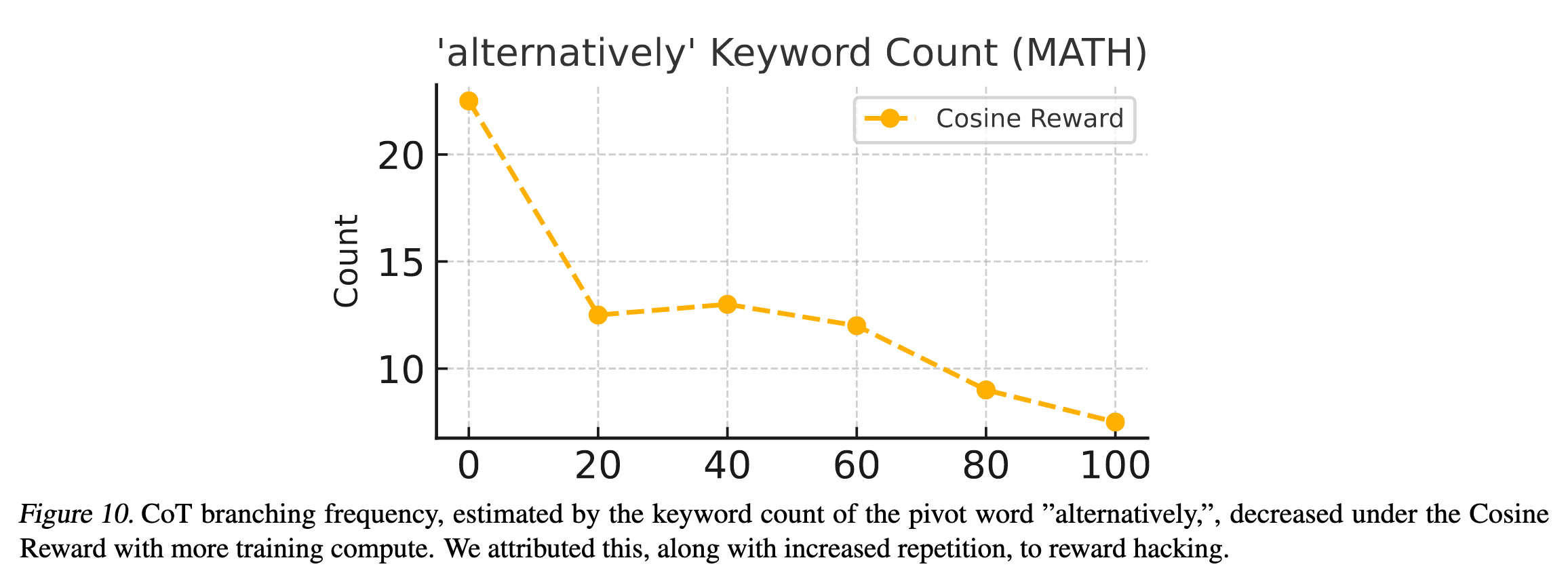
于是作者引入了 N-gram 惩罚。最终结果如下图:
4. 最佳衰减因子
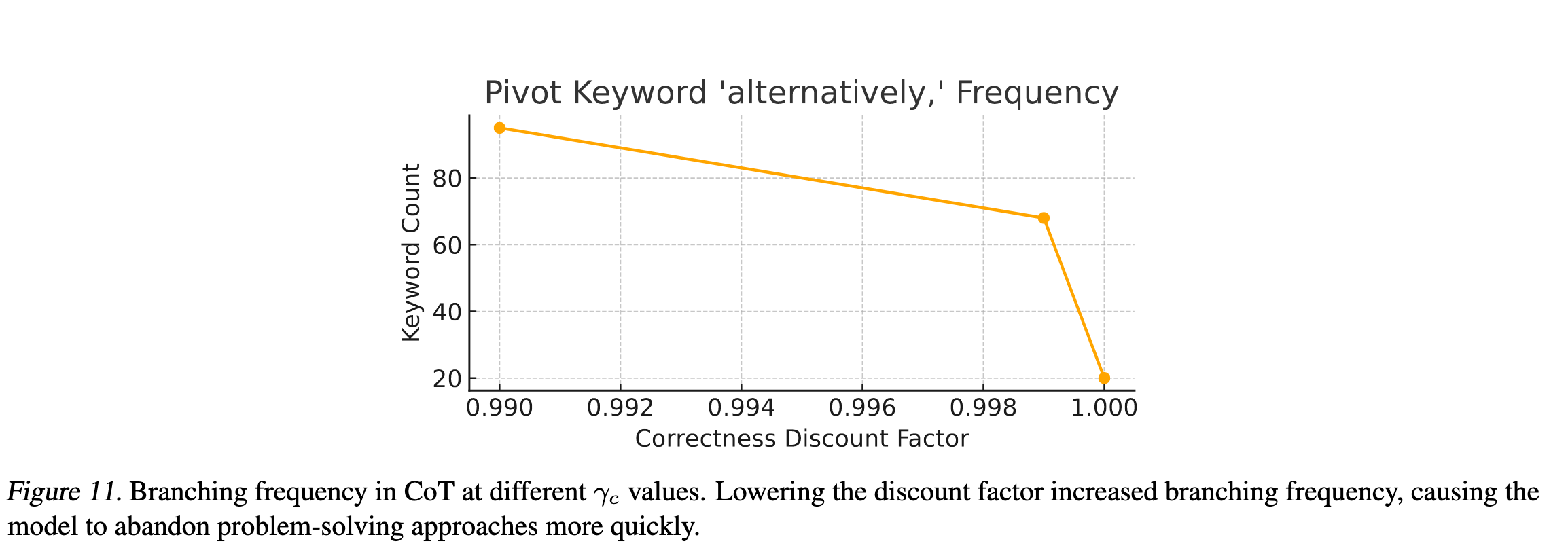
作者发现,降低的衰减因子会让模型生成更多的解决方案,更早放弃不能得到正确答案的方案。这种短视思维可能会导致模型性能下降。但作者提到,这个和生物界的延迟奖励比较相似。
5. Scaling up Verifiable Reward
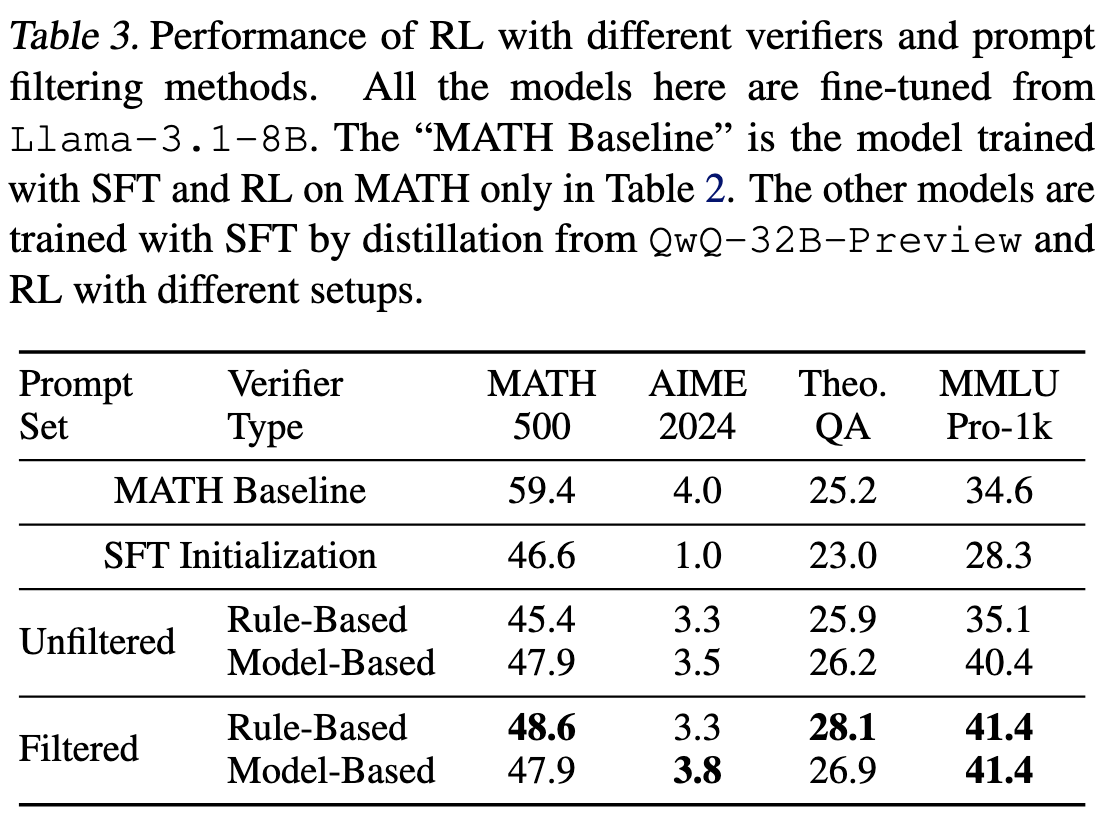
由于人工标注的高质量数据比较少,因此作者采用其他尽管噪音较多但可用的数据,例如从 Web 语料库中提取的与推理相关的 QA 对(处理后的 WebInstruct)。然后结合 MATH 数据进行了实验。结果表明,在 SFT 中加入含噪但具有多样性的数据,能够实现不同任务间的均衡性能。
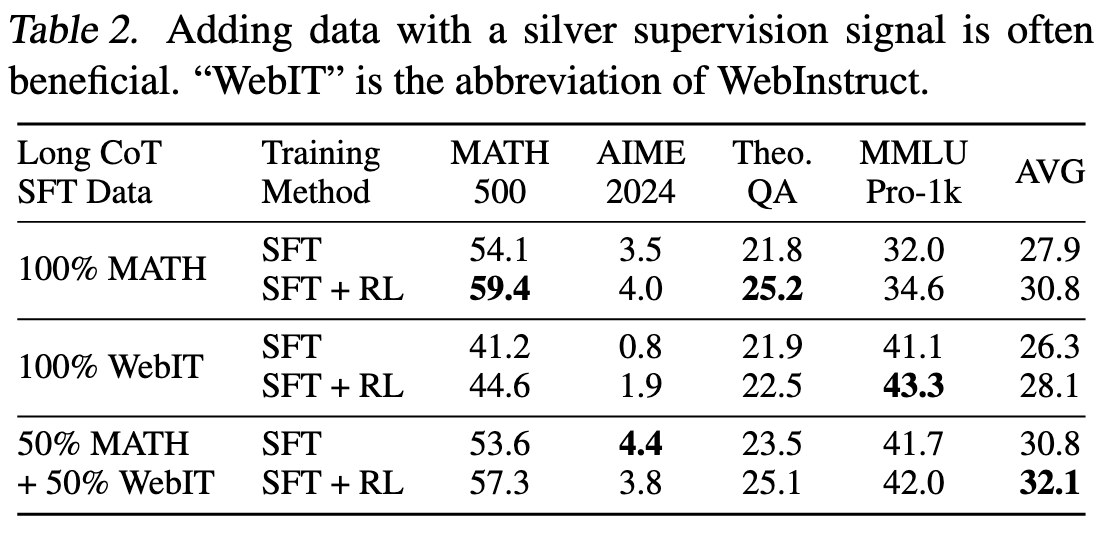
同时,作者还对比了两种从含噪可验证数据中获取奖励的主要方法:1)提取简短回答并使用基于规则的验证器;2)使用能够处理自由形式响应的基于模型的验证器。实验结果表明,在对适用于简短回答的提示集进行筛选后,基于规则的验证器效果最佳。
6. 从 Base model 探索 RL
作者对涌现现象,长度缩放也进行了一些实验。以及 Qwen2.5-Math-7B 未观察到涌现行为的潜在原因:1)作为基础模型,其规模相对较小(7B),在受到激励时可能缺乏快速发展此类复杂能力的容量。2)该模型在(持续)预训练和微调退火阶段可能过度接触类 MATH 的短指令数据,导致过拟合,从而阻碍了 Long CoT 行为的发展。
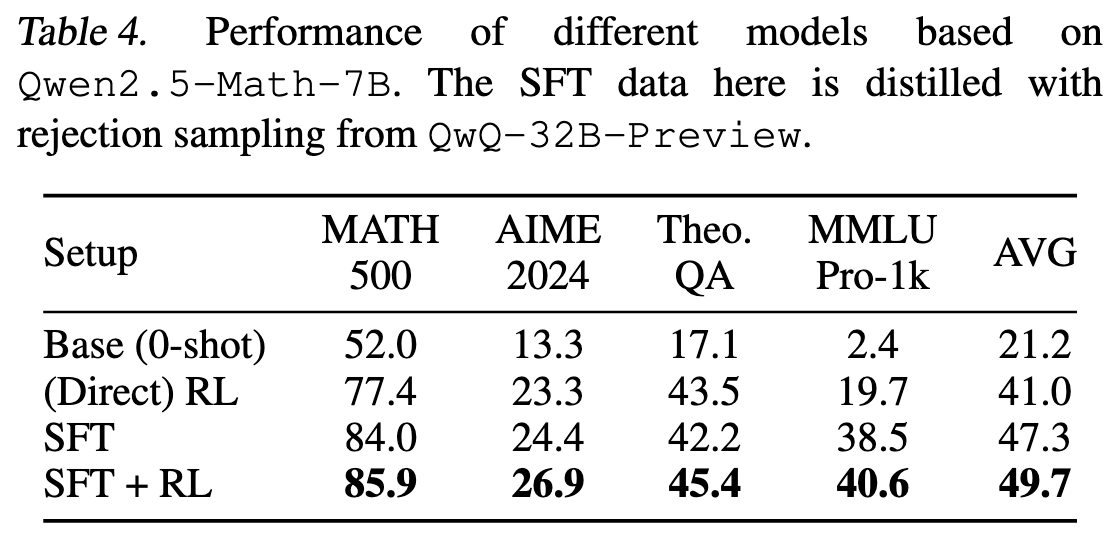
以及对 RL from the Base Model 和 RL from Long CoT SFT 的比较。
7. 笔者总结
- 这篇文章更像是由很多个小实验拼接起来的。建议读者可以去看看原文,每个小小节都可以作为单独的一部分。
Reviewer: here
References
注:若本文中存在错误或不妥之处,欢迎批评指正。








