标题: ACEBench: Who Wins the Match Point in Tool Usage?[1]
FROM arXiv 2025
写在前面:
这是一篇关于 ACEBench 相对于其他 Benchmark 的优势的文章,提及了 ACEBench 的数据构建方法和数据结构。笔者主要想借助这篇文章来介绍数据构建方式。虽然本文仅限于 ACEBench 的数据构建,但不妨碍我们借鉴其数据构建方式,来构建我们自己的 Benchmark 和 业务数据集。
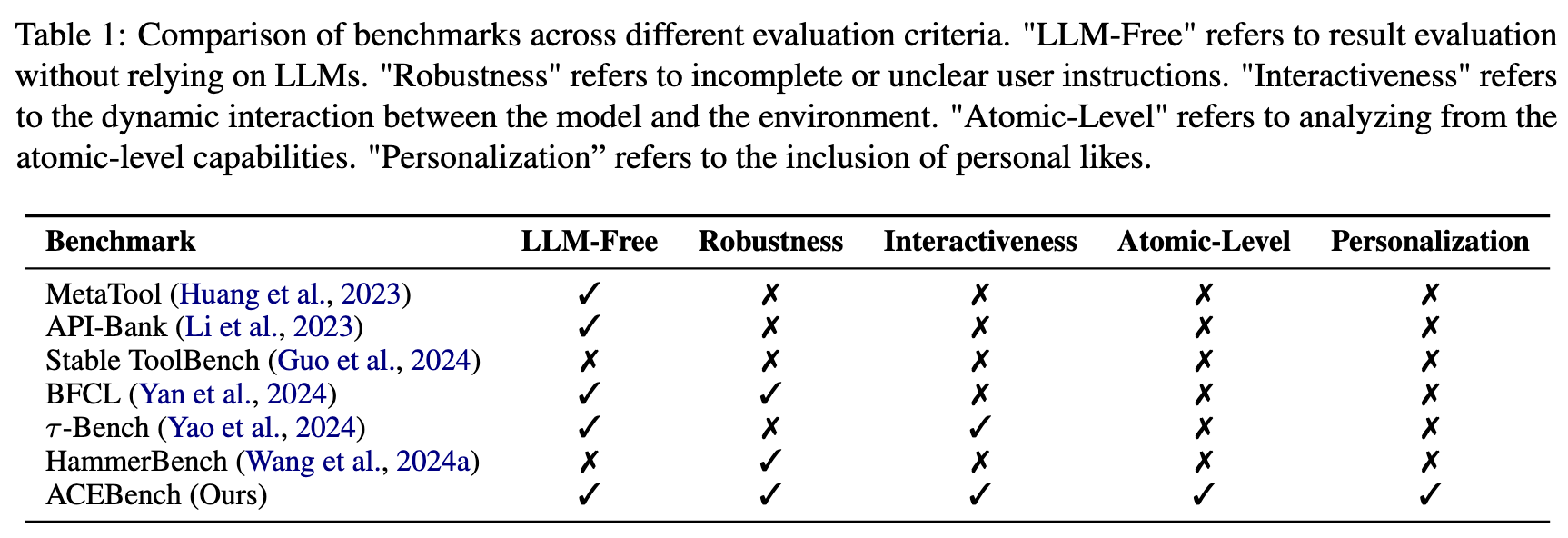
现有的评估 LLM 工具调用的 Benchmark 的缺点:
-
有限的评估场景,通常缺乏在真实多轮对话背景下的评估;BFCL 和 HammerBench 中的多轮对话,均由预先定义好的固定内容组合构成。 -
评估维度狭窄,对 LLM 如何使用工具的详细评估不够; -
依赖 LLM 或真实 API 执行进行评估,导致了大量的评估开销。
为了解决这些挑战,作者引入了 ACEBench,这是一个评估 LLM 中工具使用情况的综合基准。ACEBench 根据评估方法将数据分为三种主要类型:Normal、Special 和 Agent。
-
“Normal”评估基本场景中的工具使用情况;由固定的问答对组成,包含多种场景,单回合对话、多回合对话和个性化场景数据。它还包括对原子级能力的评估。 -
“Special”评估指令不明确或不完整情况下的工具使用情况;包括不完善的指令,例如不完整参数、格式不正确的参数或与候选函数的功能无关的问题。 -
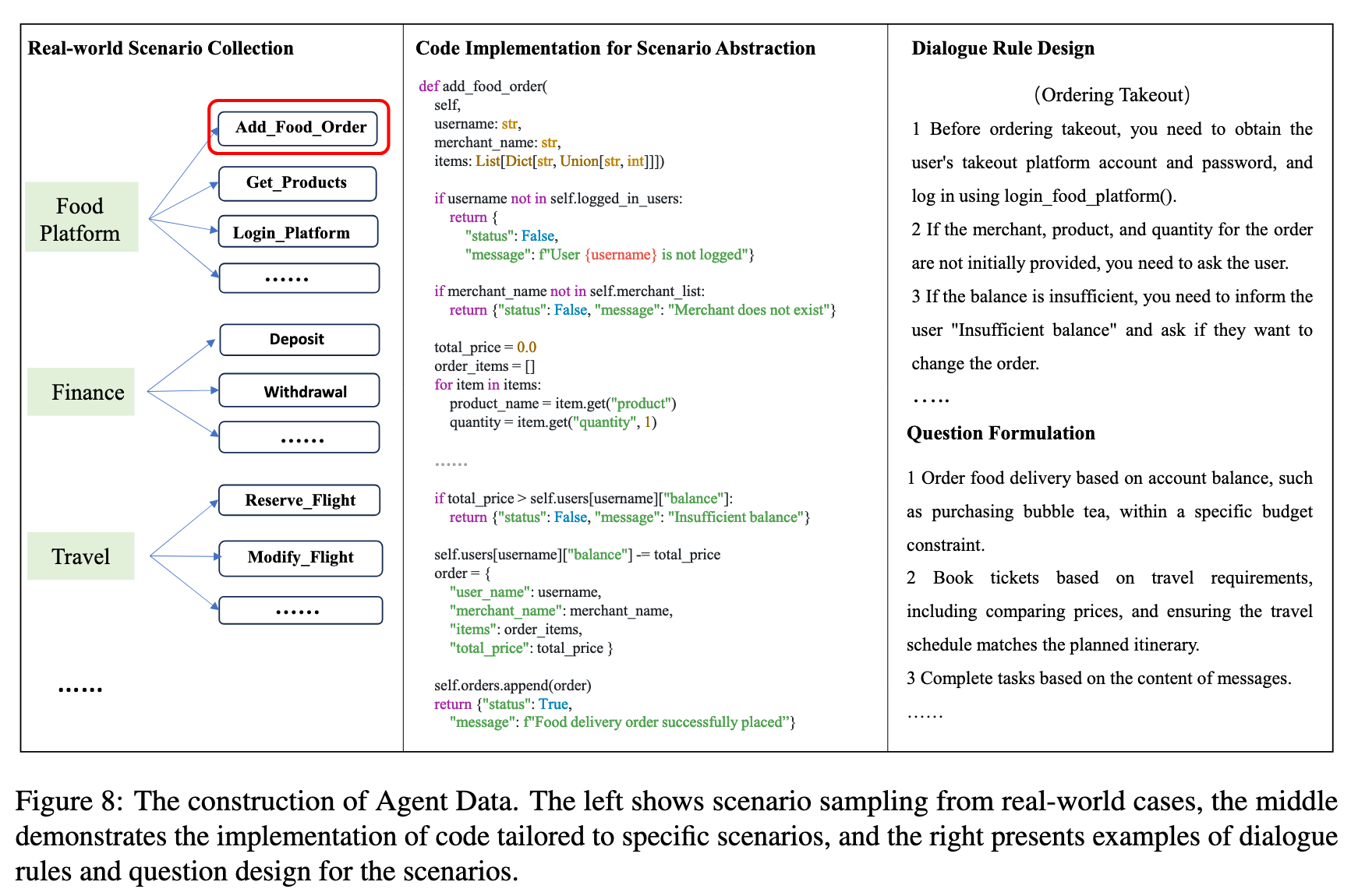
“Agent”通过多代理交互来评估工具使用情况,以模拟真实世界的多回合对话。包含真实场景,抽象构建多回合、多步骤的工具调用场景,根据用户是否参与对话过程分为多回合和多步骤案例。
1. 数据
作者构建了 2000 个带标注的 entiries,包含中英两种语言。保障数据分布平衡。构建流程如下图所示:
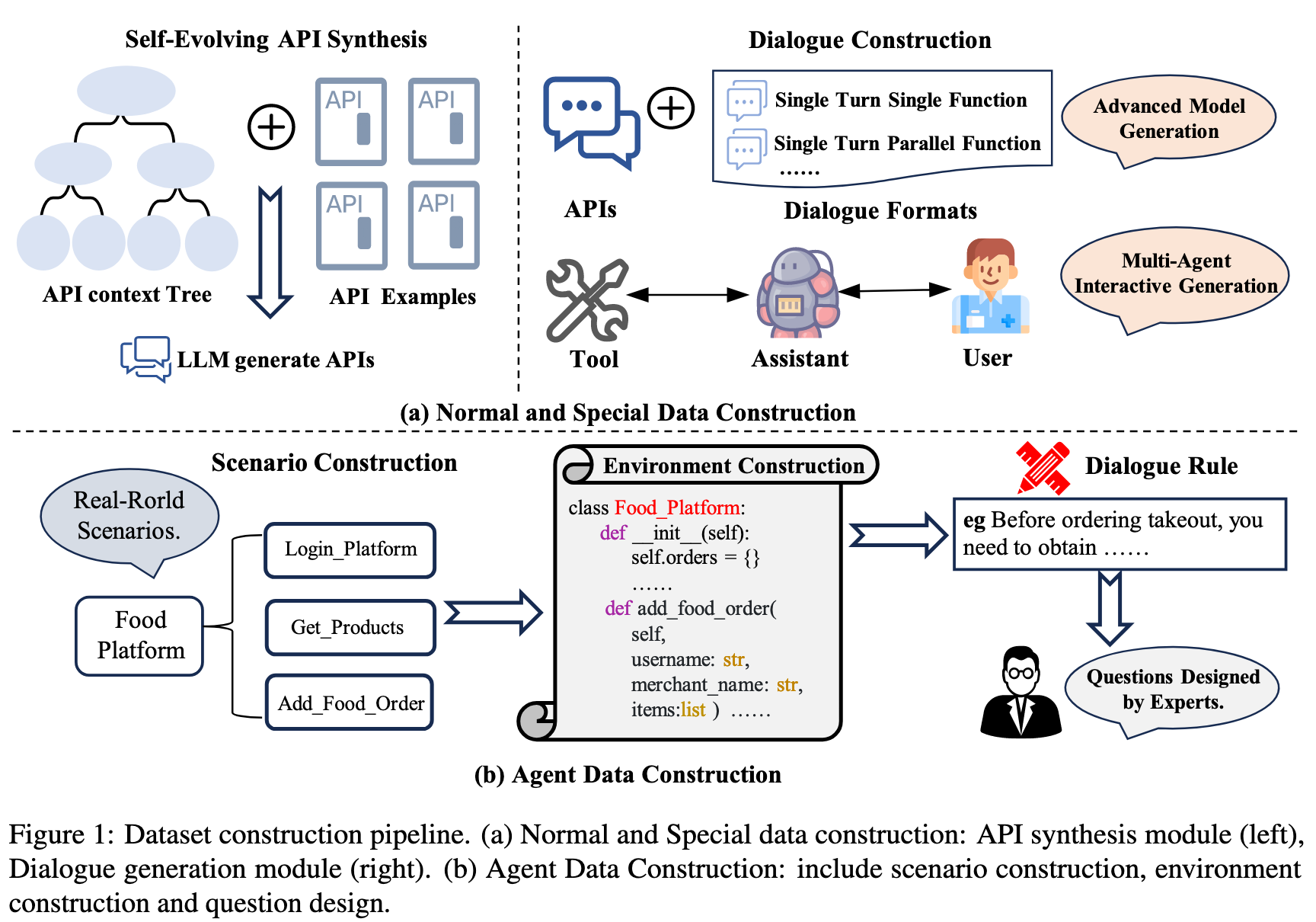
API context Tree: 使用合成 API 来构建评估数据集,并以现实世界的 API 作为指导。采用 self-evolution 方法,构建分层 API 上下文树,以确保生成的 API 涵盖广泛的领域和功能。(但作者并没有说明 self-evolution 的具体方法)
Dialogue Generation: 构建了两个不同的对话生成 pipline。第一个:从 API 池中选择 3-6 个候选 API 来生成对话(大部分是随机选择,其他的特殊场景用特定方法)。第二个:multi-agent dialogue pipeline 来模拟现实世界的交互(user, assistant, and tool)。
1.1. 数据结构
Normal 和 Special 数据由大模型生成;Agent 数据由专家构建。结构如下图所示:


1.2. 数据清洗
通过基于规则的方式,基于大模型的方式和人工过滤的方式来对最终数据进行清洗。
1.3. 数据分析
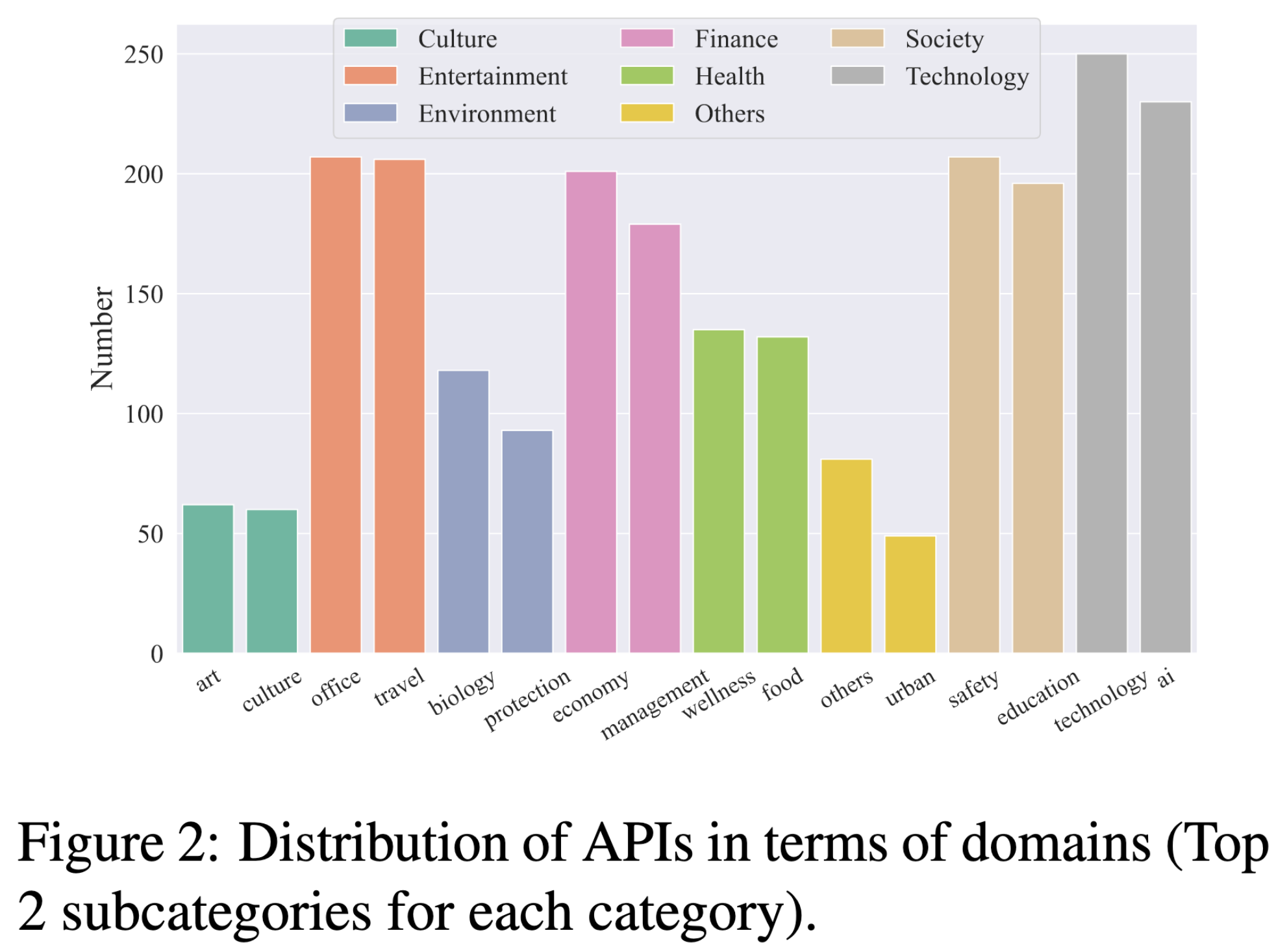
API 分布: ACEBench API 覆盖 8 大领域和 68 个子领域,共 4538 个中英文 API。分布如下图所示:
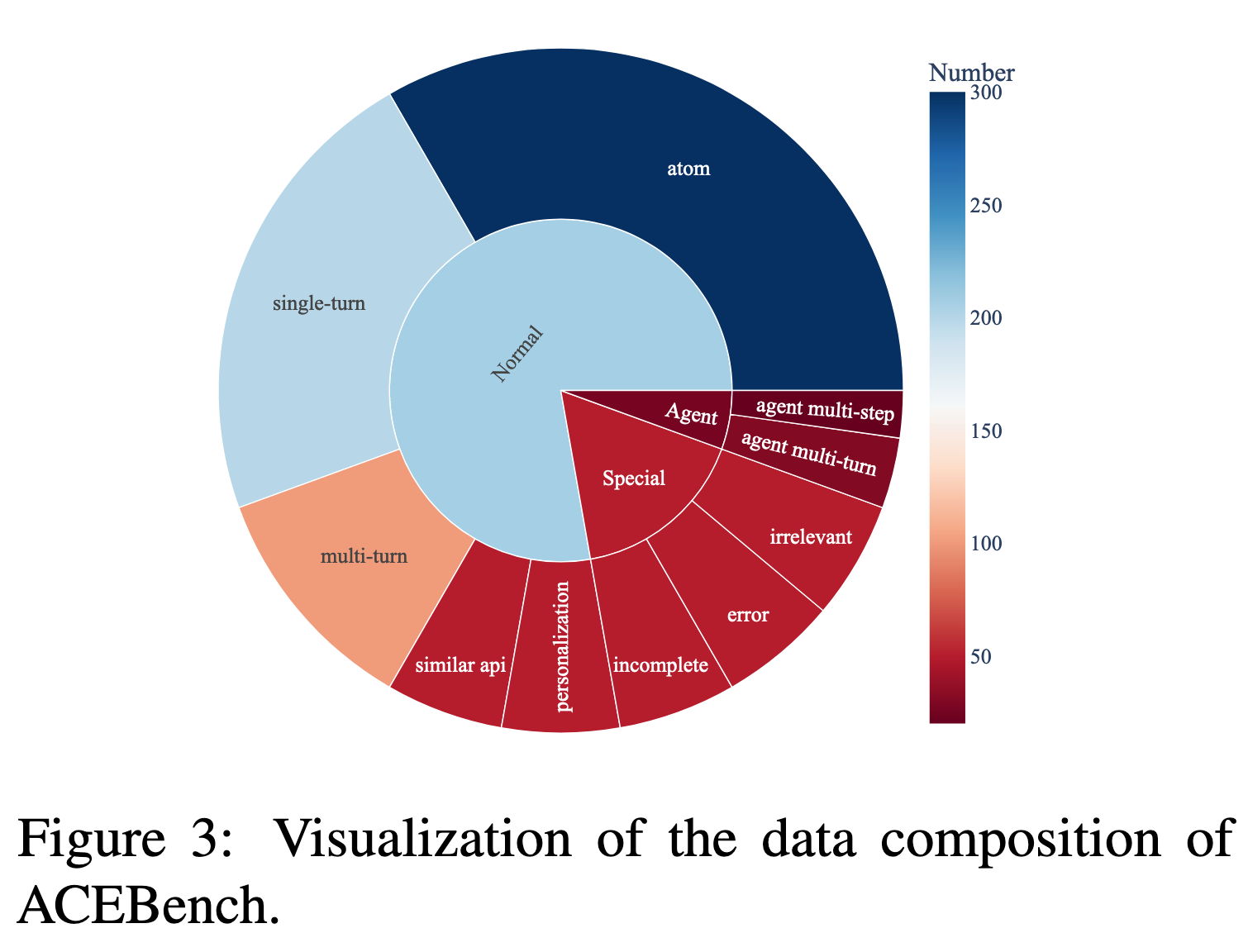
数据构成: 如下图所示:
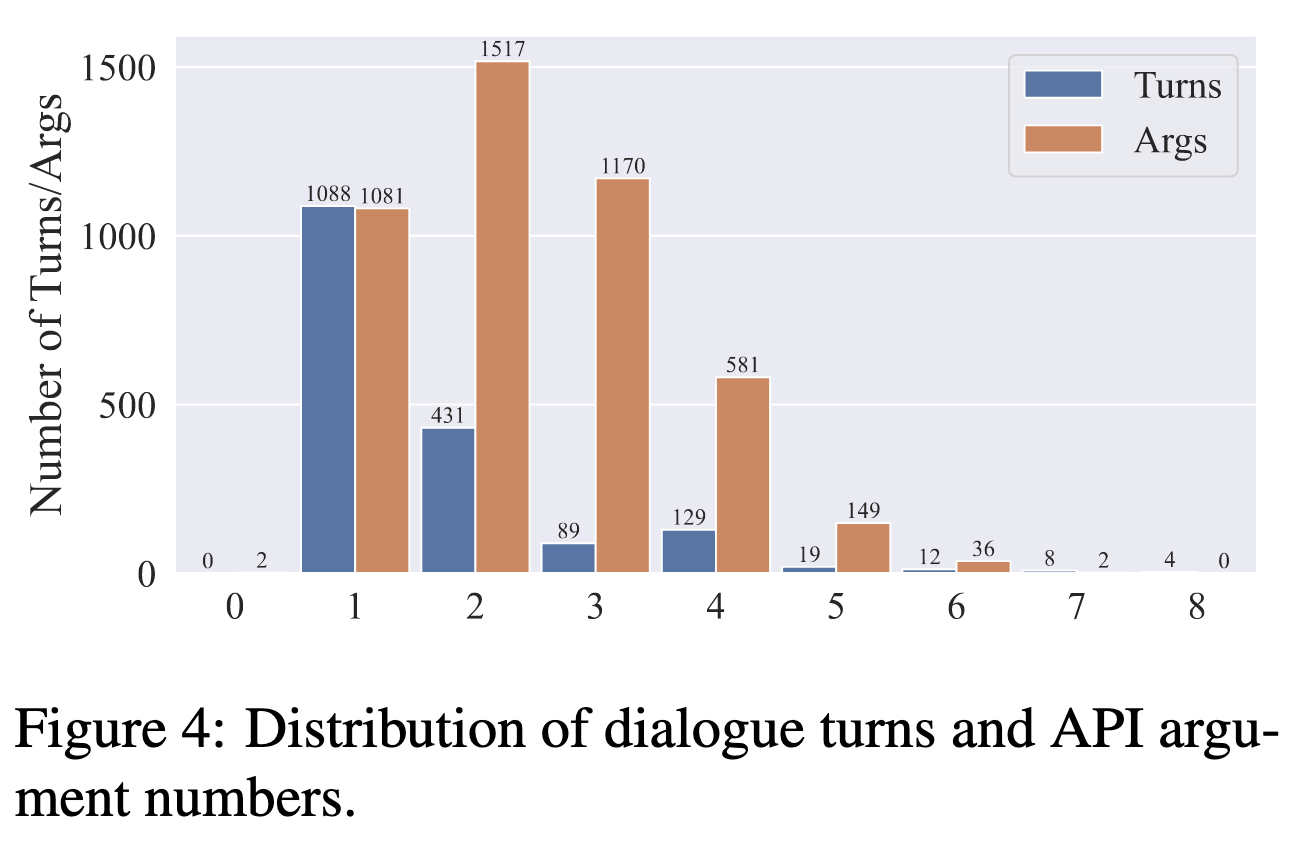
对话轮次和参数数量: 基本都在 1-8 轮之间。如下图所示:
2. 评估
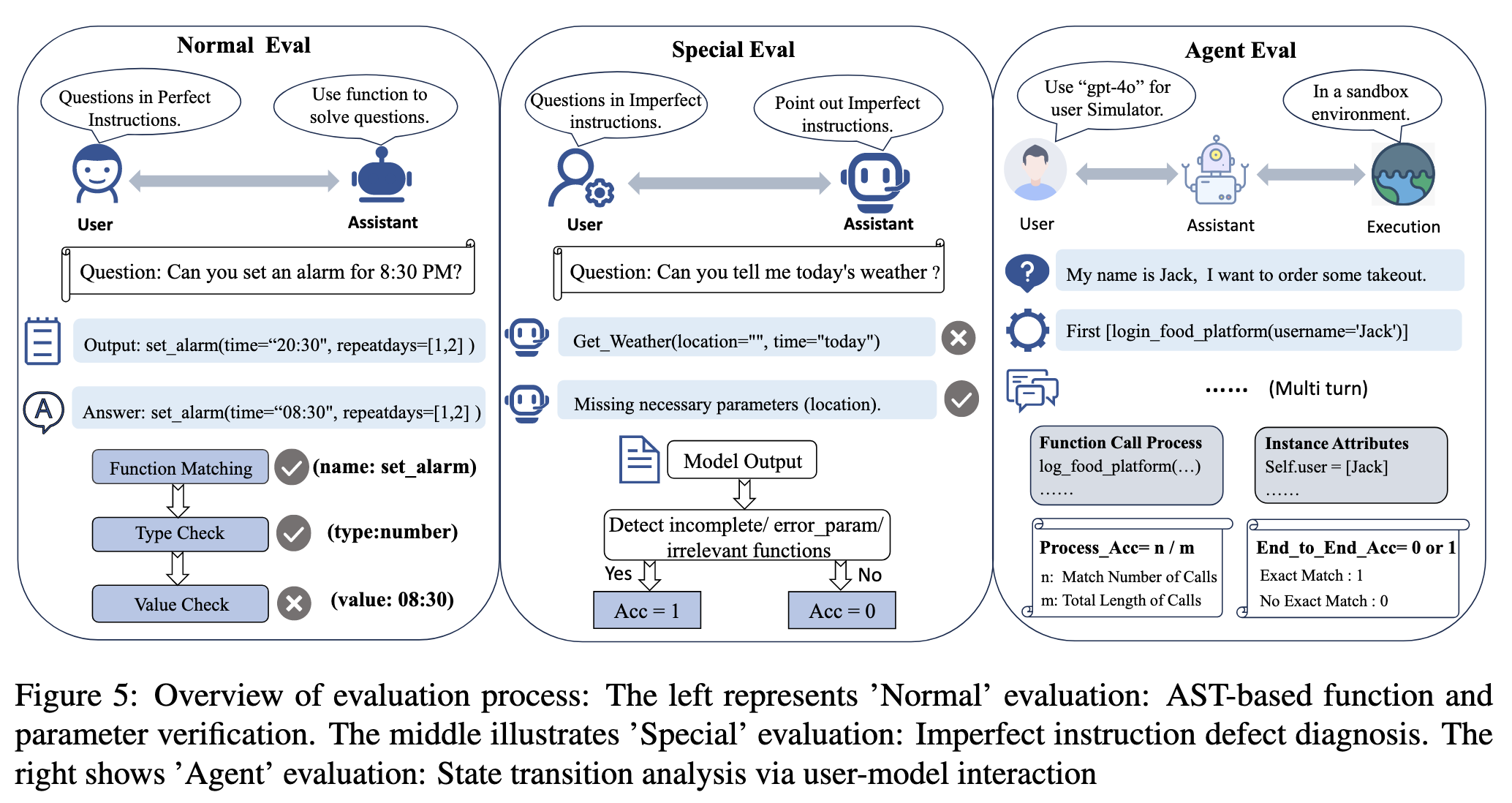
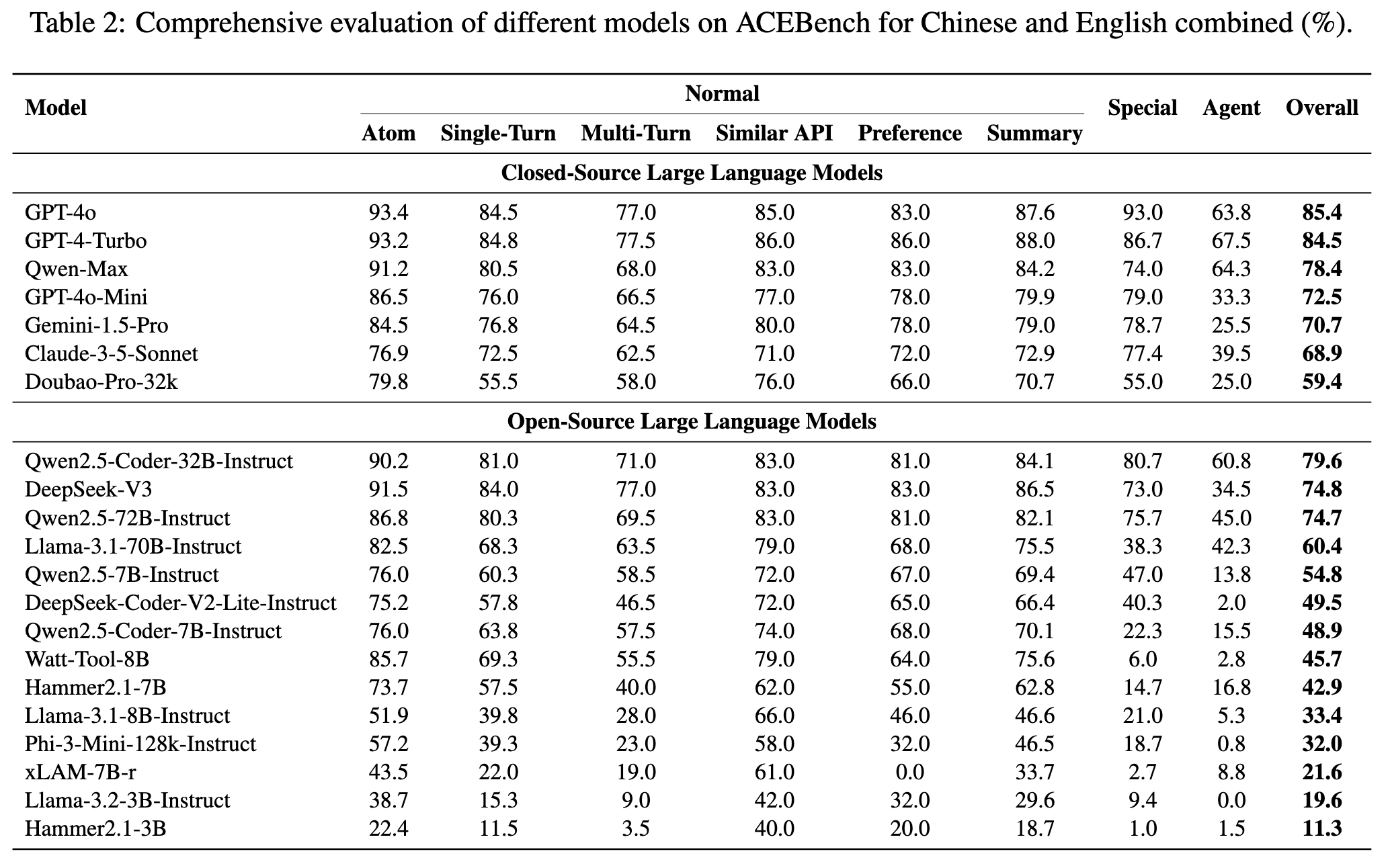
2.1 Normal
通过 AST 解析将模型的函数调用输出与 GT 进行对比,对于存在多个有效答案的情况,匹配一个即为为正确。
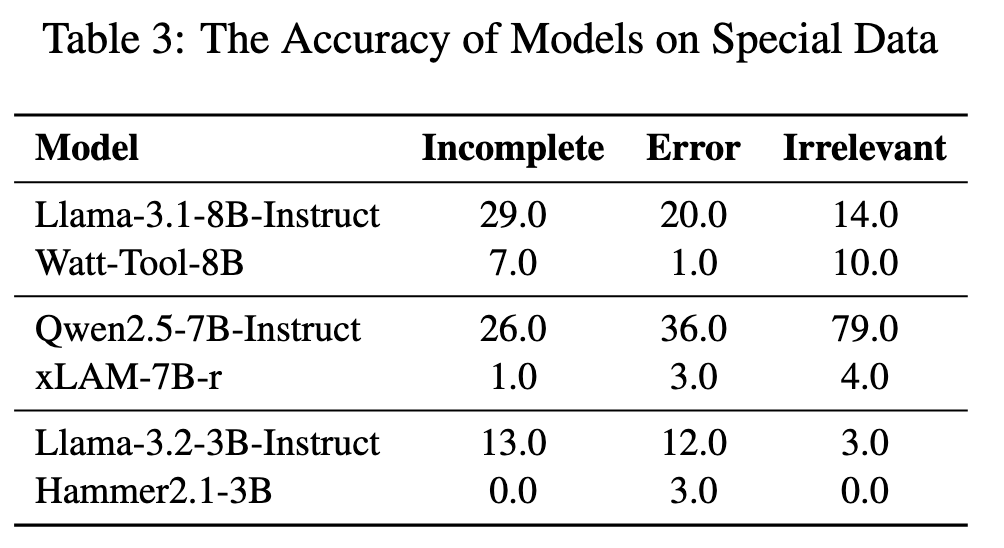
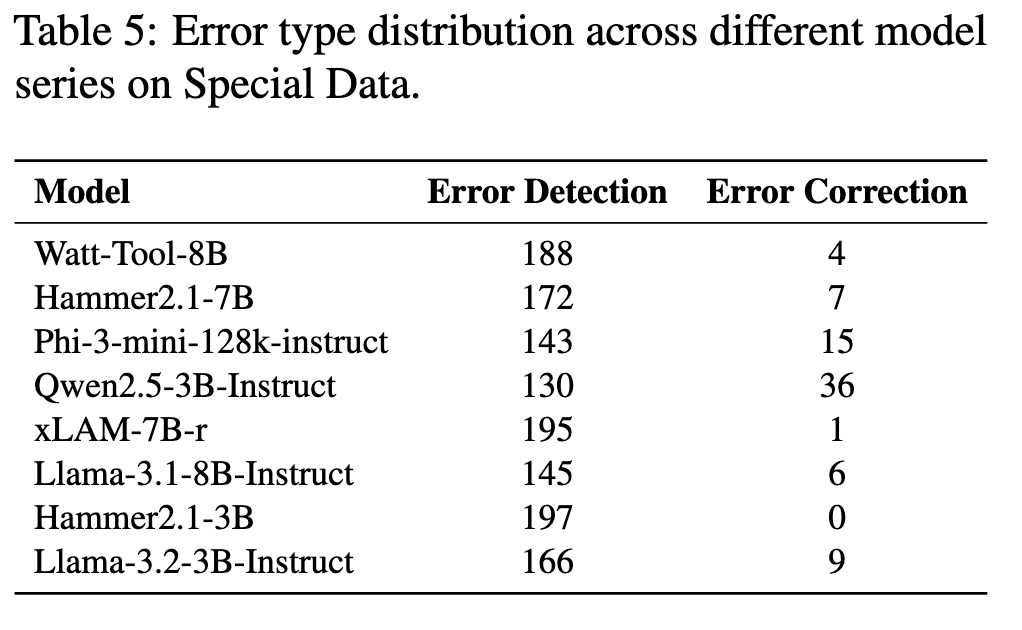
2.2 Special
评估重点在于考察模型的问题识别能力。模型需满足以下要求:(1)检测并提示缺失的参数;(2)准确定位存在错误的参数;(3)识别任务与函数不匹配的情况。对于每个案例,若模型能正确识别上述问题则准确率得 1 分,否则得 0 分。
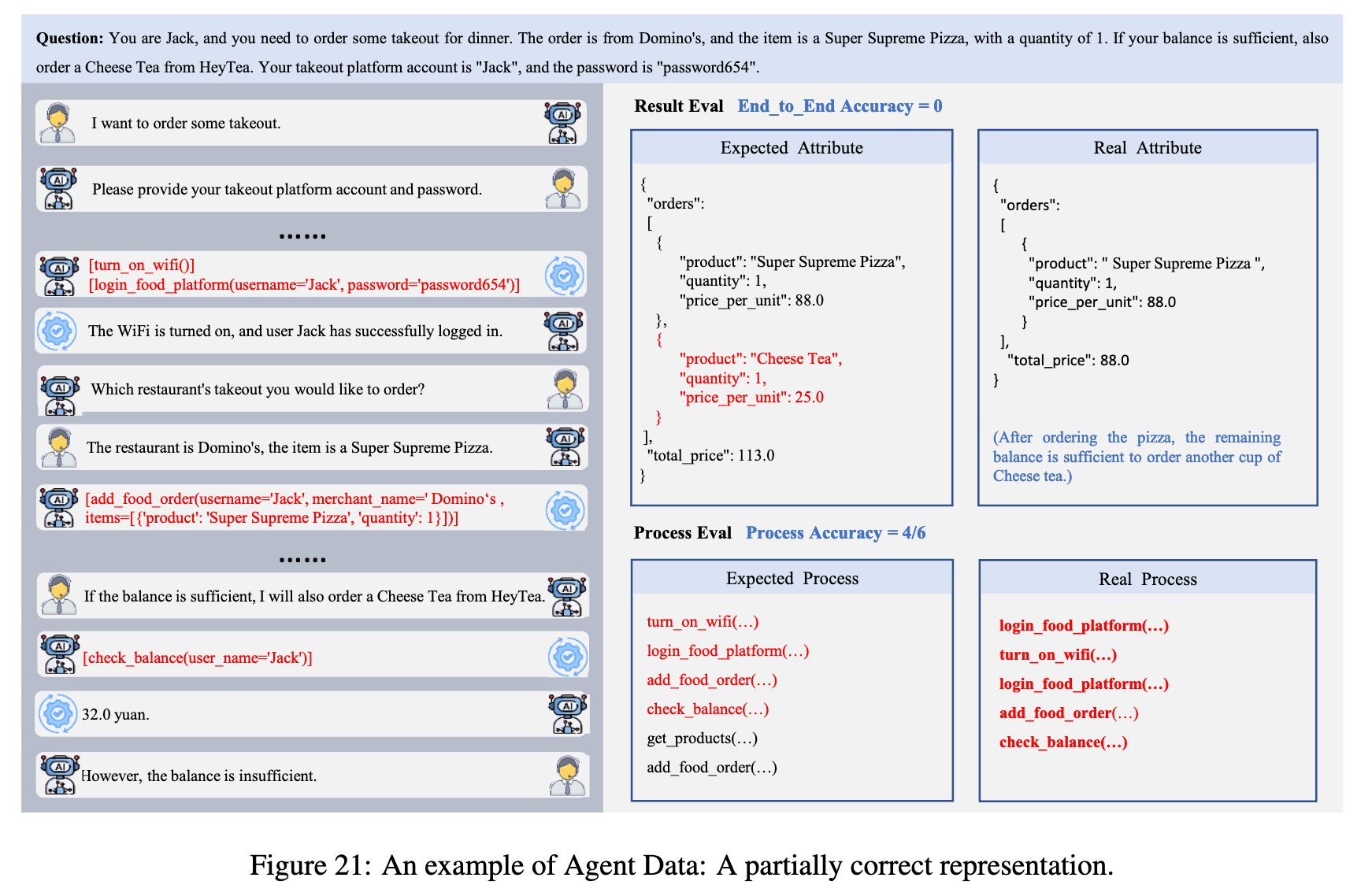
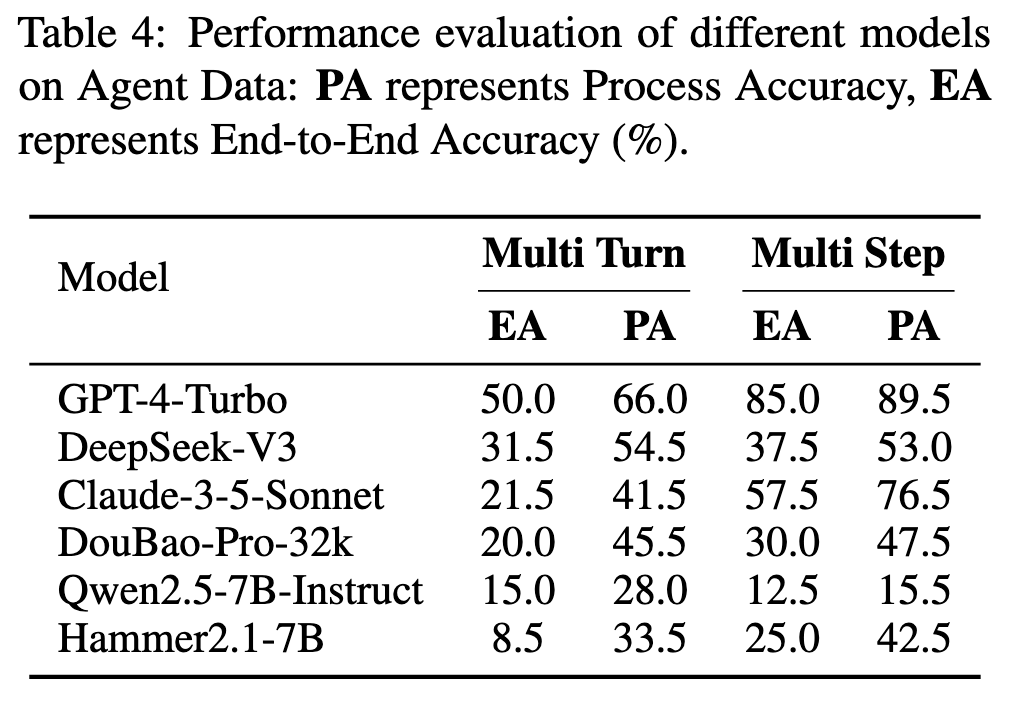
2.3 Agent
测试中采用 gpt-4o 作为用户模拟器。评估包含两个指标:端到端准确率通过将对应类别的实例属性与目标进行对比来评估,若所有属性完全匹配,则准确率为 1,否则为 0;过程准确率由实际函数调用过程与理想过程的一致性决定,用 n/m 表示,其中 m 代表理想的函数调用过程,n 代表实际过程与理想过程的匹配程度。
2.4 Overall
总体准确度计算为”Normal”, “Special”和”Agent”数据类型的准确度的加权和,其中权重由其各自样本量的平方根决定。

3. 实验
4. 笔者总结
-
这是一篇关于 ACEBench 相对于其他 Benchmark 的优势的文章,提及了 ACEBench 的数据构建方法和数据结构。笔者主要想借助这篇文章来介绍数据构建方式。虽然本文仅限于 ACEBench 的数据构建,但不妨碍我们借鉴其数据构建方式,来构建我们自己的 Benchmark 和 业务数据集。
5. References
6. Appendix
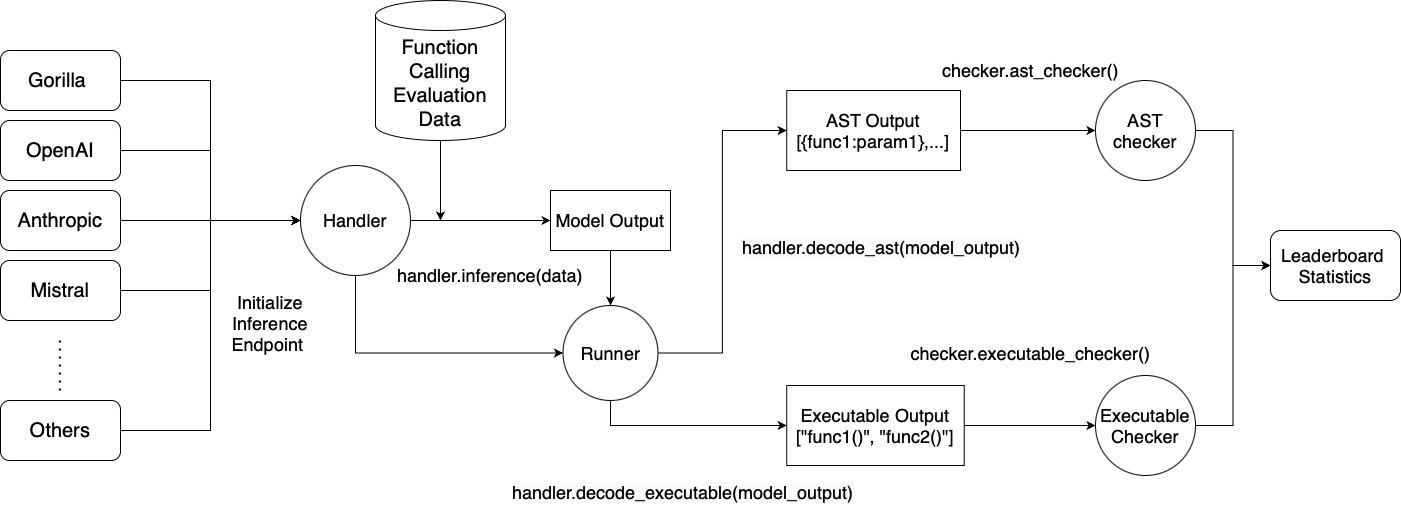
6.1. BFCL(Berkeley Function Calling Leaderboard)
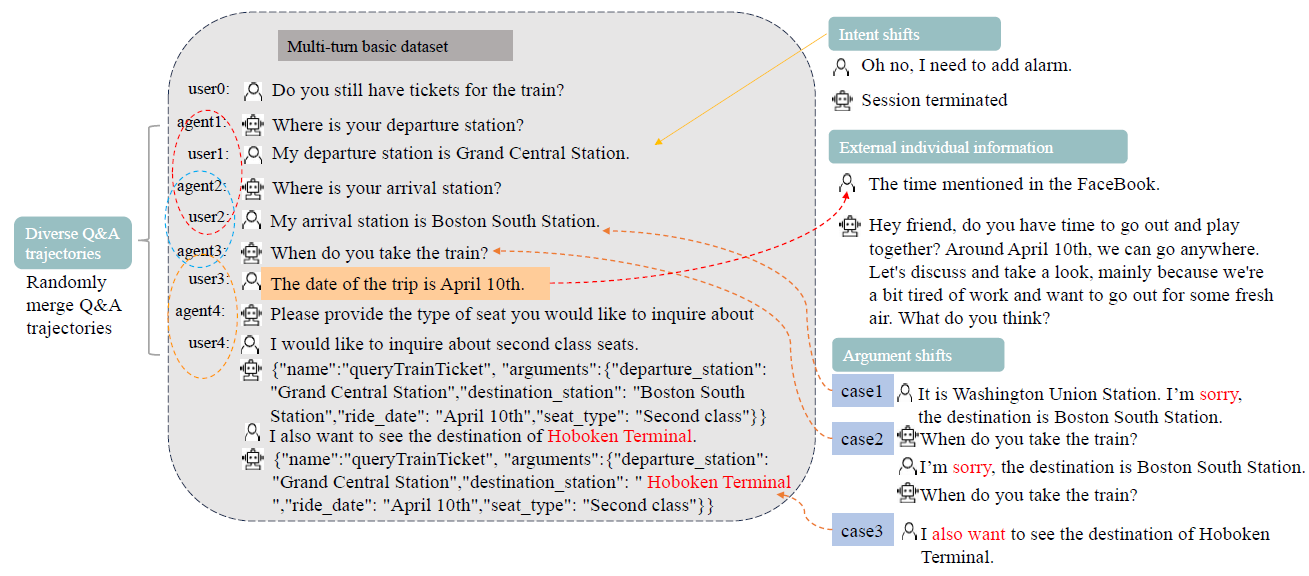
6.2. HammerBench
6.3. ACEBench – Normal Examples



6.4. ACEBench – Special



6.5. ACEBench – Agent