
本文最后更新于 96 天前,其中的信息可能已经有所发展或是发生改变。
标题: On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes[1]
FROM ICLR 2024 Google DeepMind arXiv
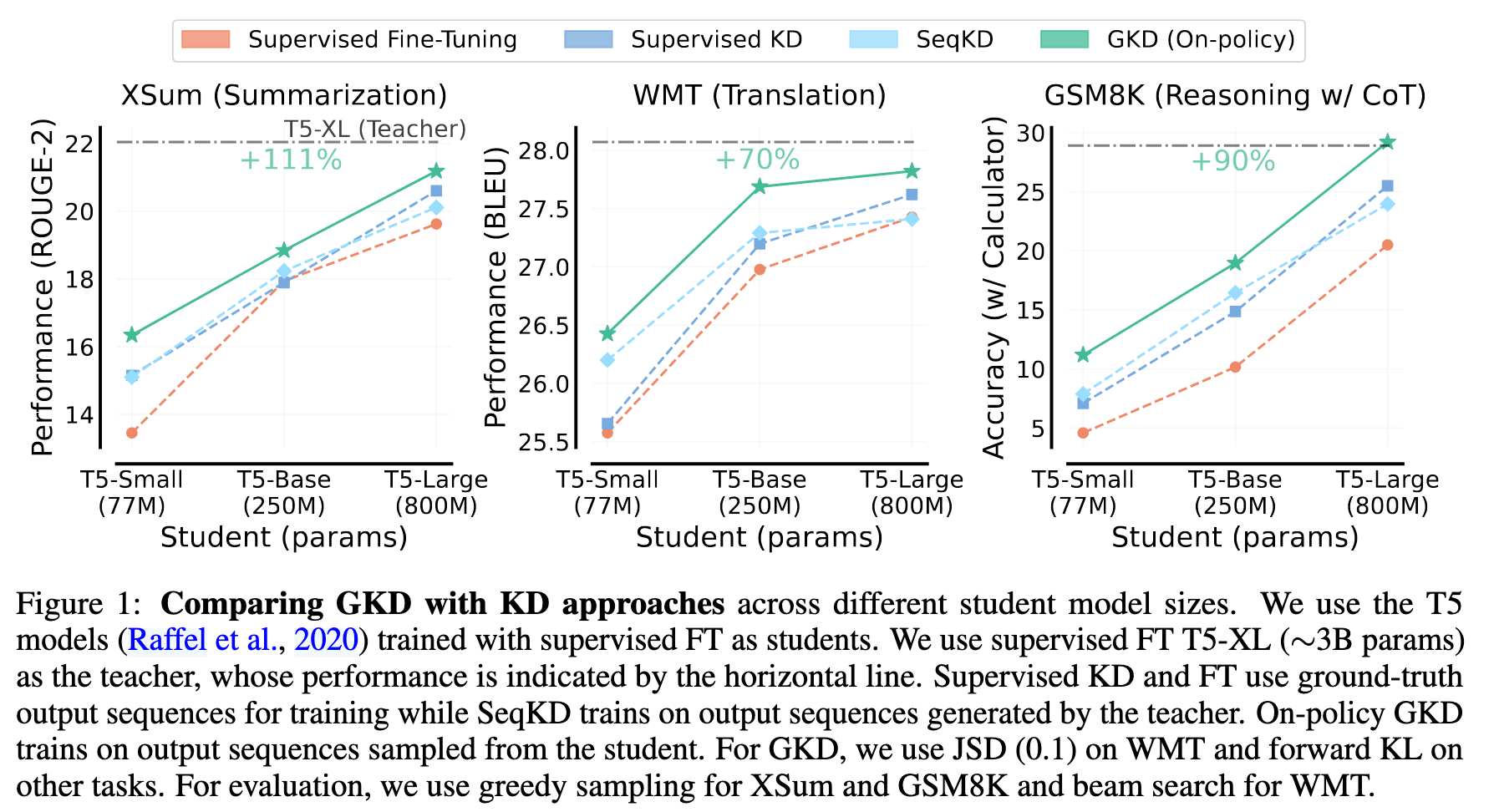
通用的 KD(Knowledge Distillation) 方法存在教师模型输出和学生模型输出分布不一致的问题。于是作者提出了 GKD(Generalized Knowledge Distillation),主要特点是:
-
用学生模型自己的输出进行训练 -
可以灵活替换损失函数(reverse KL 或 JSD 这种。但是常规的蒸馏也可以替换)
关于分布不一致的问题,作者主要指的是正向 KL 散度导致的 Model-covering 的问题。感兴趣的读者可以见之前的文章也有提到这点 here
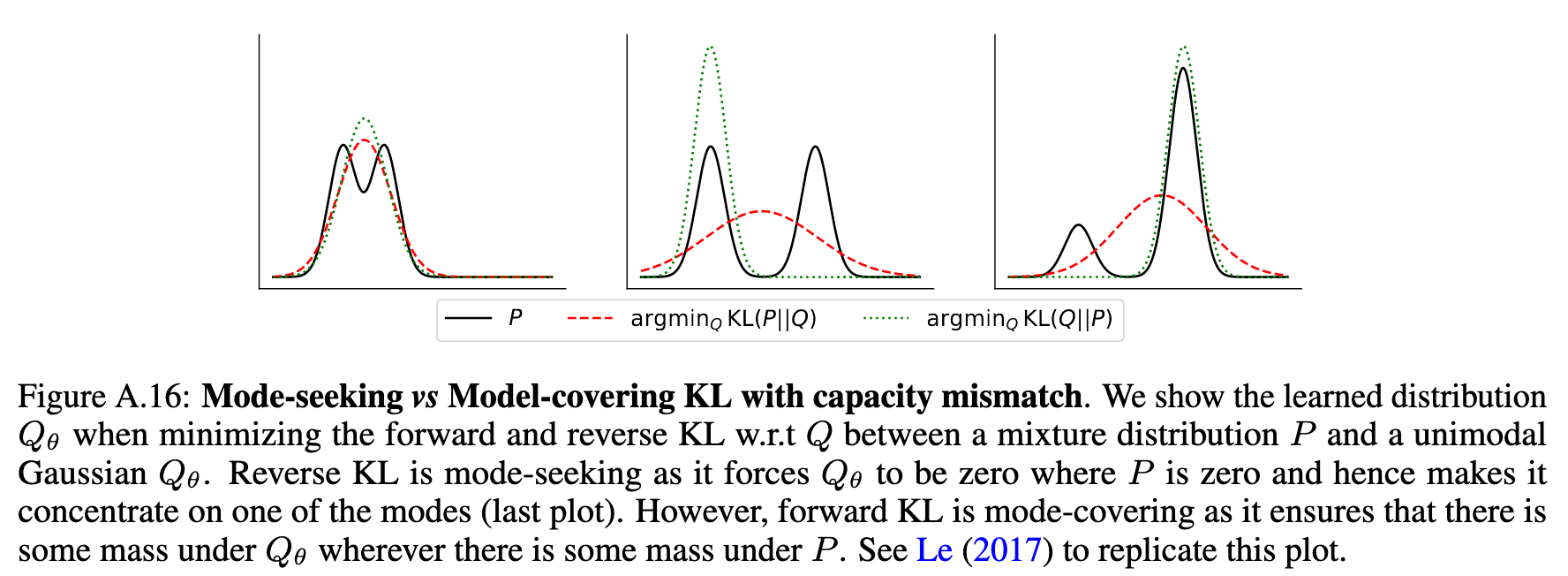
1. GKD
1.1 on-policy KD
\[L_{OD}(\theta) := \mathbb{E}_{x \sim X} \left[ \mathbb{E}_{y \sim p_S(\cdot | x)} \left[ \mathcal{D}_{KL} \left( p_T \parallel p_S^\theta \right) (y | x) \right] \right]\]
1.2 generalized KD
\[L_{\text{GKD}}(\theta) := (1 – \lambda) \mathbb{E}_{(x, y) \sim (X, Y)} \left[ \mathcal{D}(p_{\text{T}} \Vert p_{\text{S}}^{\theta})(y \vert x) \right] + \lambda \mathbb{E}_{x \sim X} \left[ \mathbb{E}_{y \sim p_{\text{S}}(\cdot \vert x)} \left[ \mathcal{D}(p_{\text{T}} \Vert p_{\text{S}}^{\theta})(y \vert x) \right] \right]\]
\[\mathcal{D} \big( p_{\text{T}} \Vert p_{\text{S}}^{\theta} \big) (y \vert x) := \frac{1}{L_y} \sum_{n=1}^{L_y} \mathcal{D} \big( p_{\text{T}}(\cdot \vert y_{<n}, x) \Vert p_{\text{S}}^{\theta}(\cdot \vert y_{<n}, x) \big)\]
其中 \(D(p_{\text{T}}, p_{\text{S}})(y \vert x)\) 是教师和学生分布之间的 token 级别的散度。\(\lambda \in [0, 1]\) 是一个超参数,控制学生模型生成数据的比例(也就是 on-policy 的比例)。
1.3 RL + on-policy GKD
\[\mathbb{E}_{x \sim X} \left[ (1 – \alpha) \underbrace{\mathbb{E}_{y \sim p_S^\theta(\cdot | x)} [r(y)]}_{\text{RL objective}} – \alpha \underbrace{\mathbb{E}_{y \sim p_S(\cdot | x)} [\mathcal{D}(p_T \parallel p_S^\theta)(y | x)]}_{\text{Generalized On-Policy Distillation}} \right]\]
2. 实验
2.1 不同 divergence 的对比
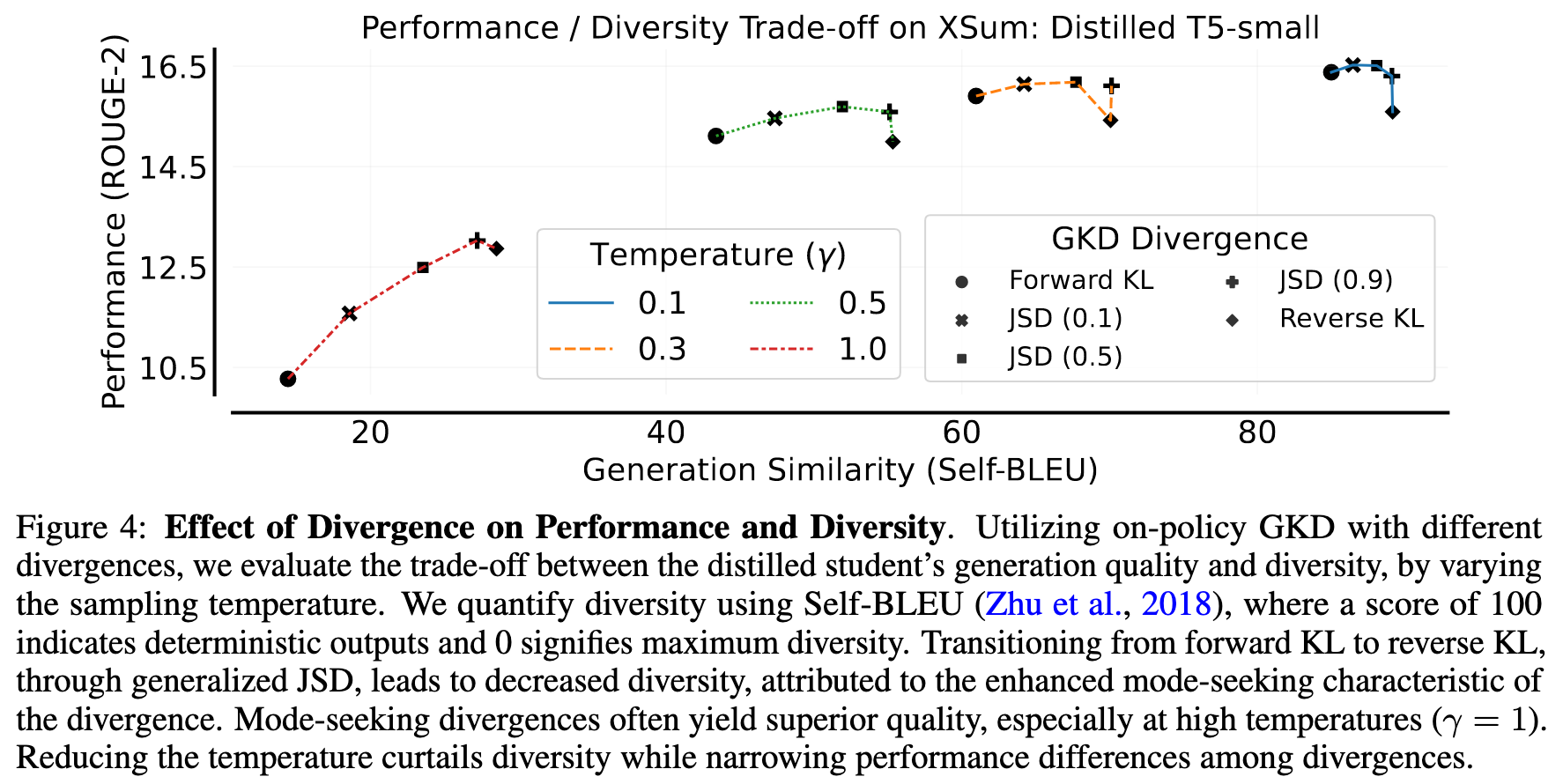
2.2 RL + on-policy GKD
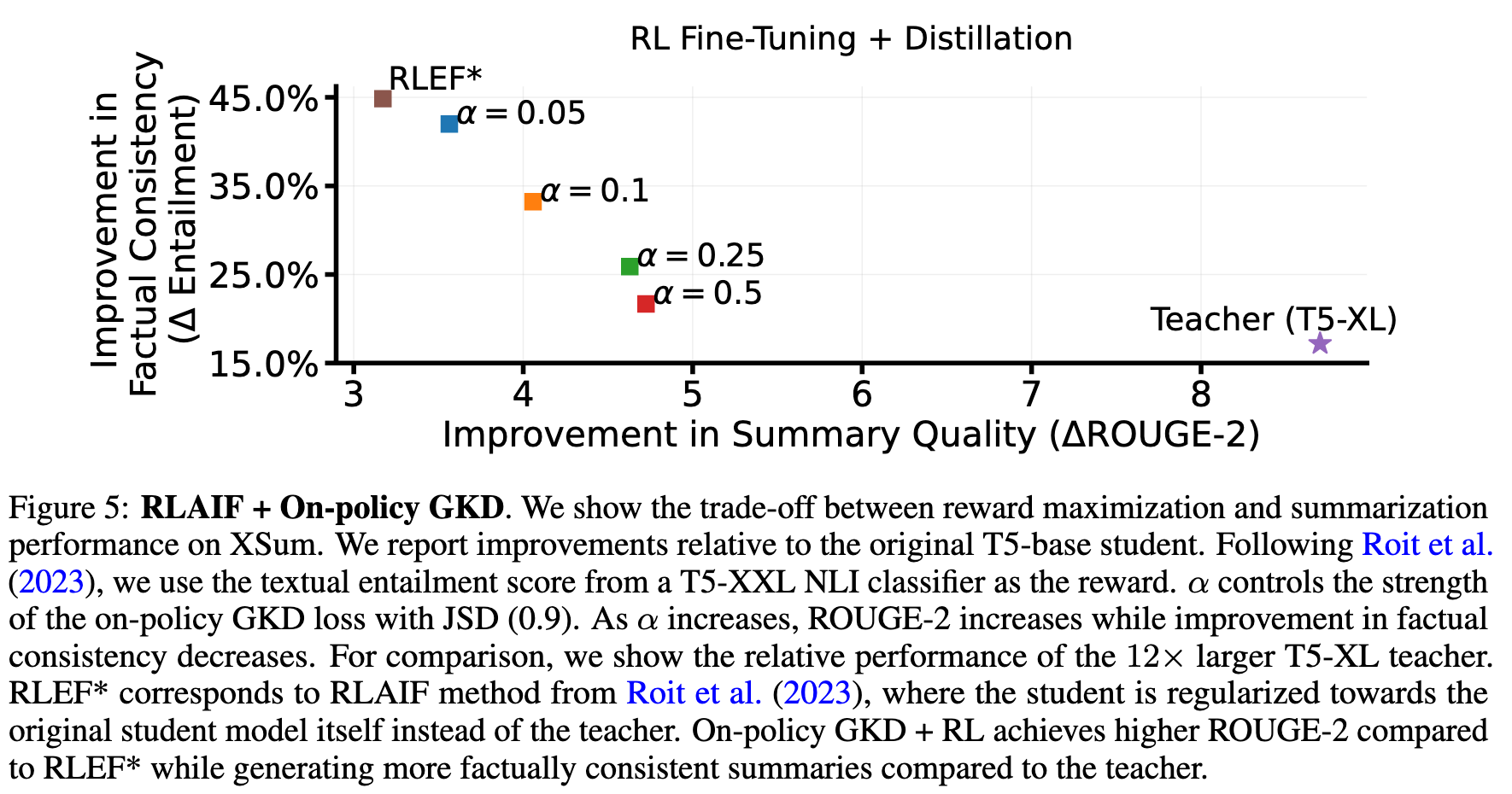
2.3 摘要提取
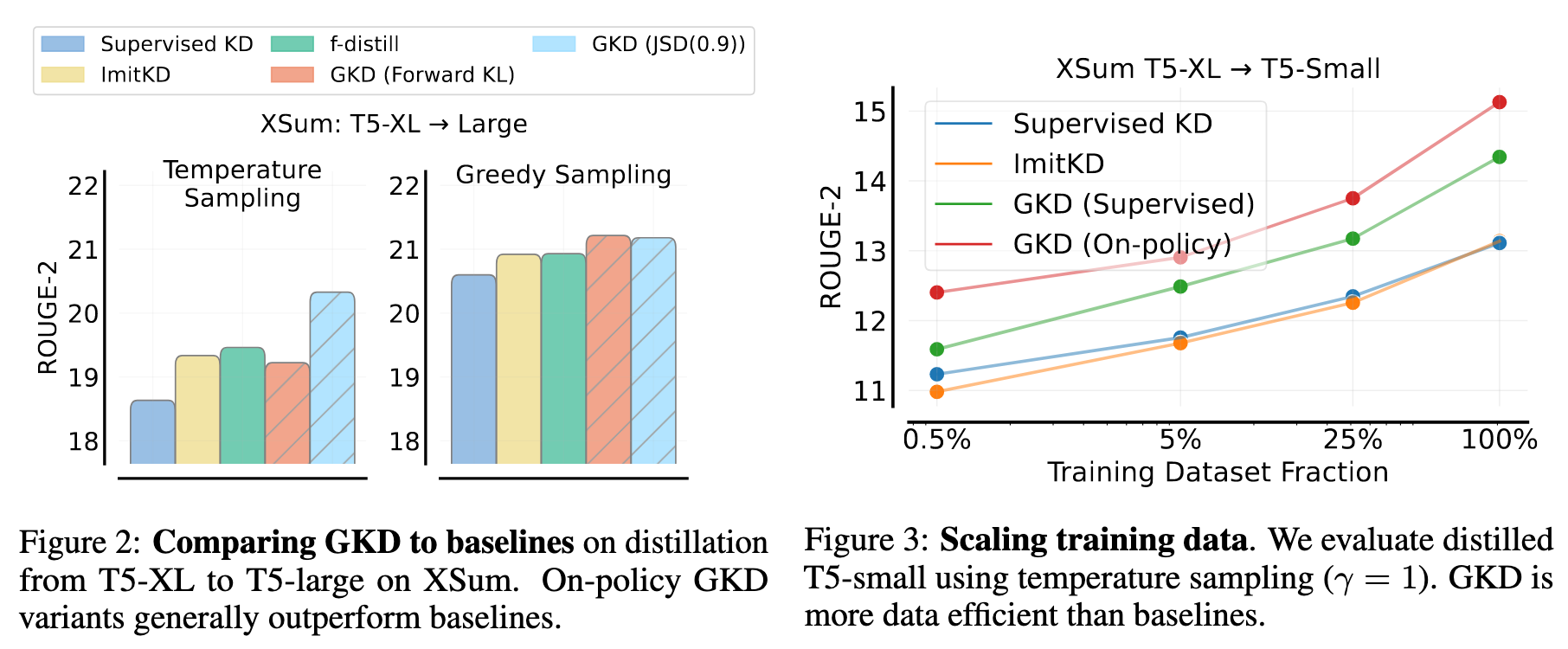
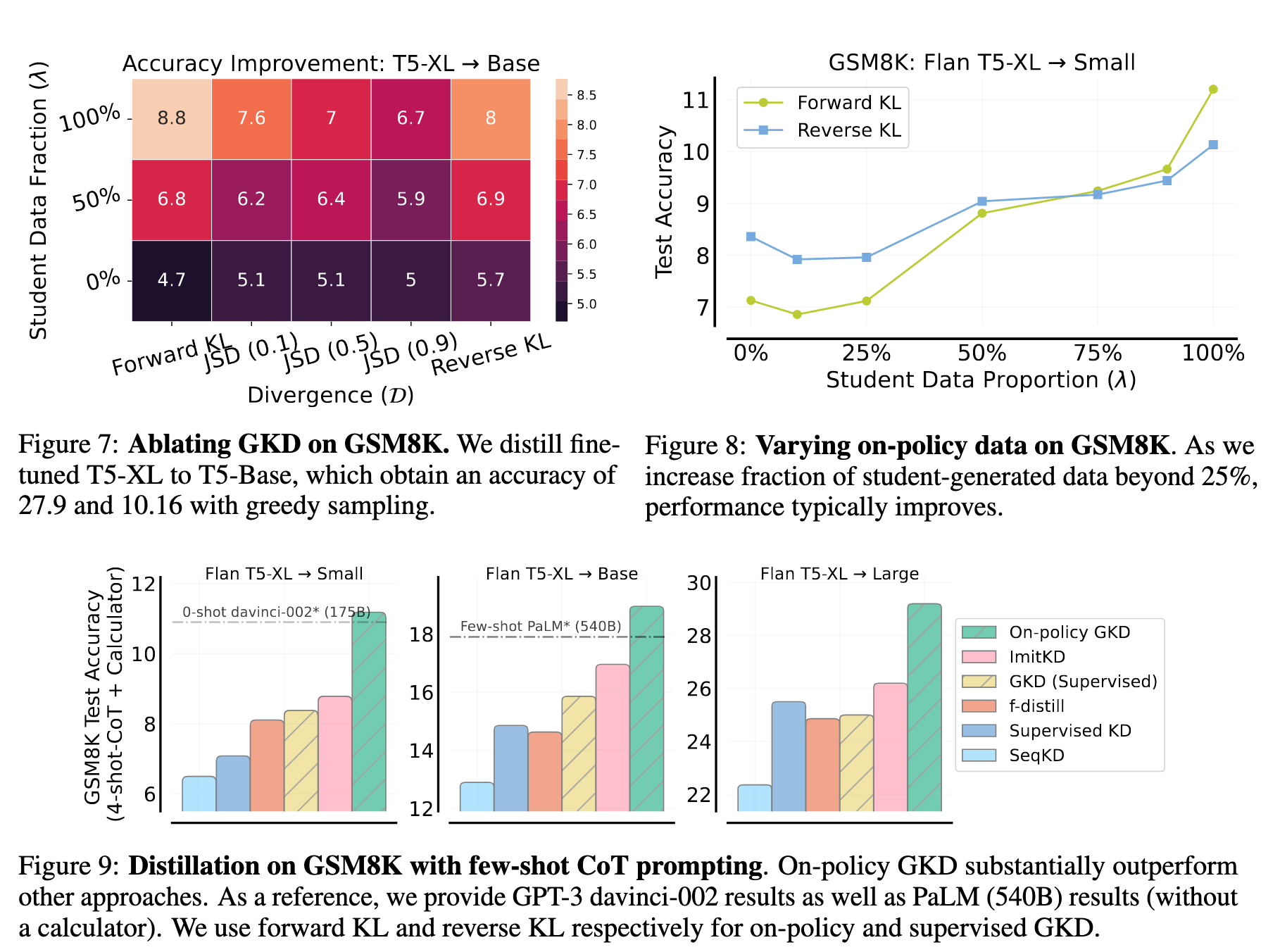
2.4 数学
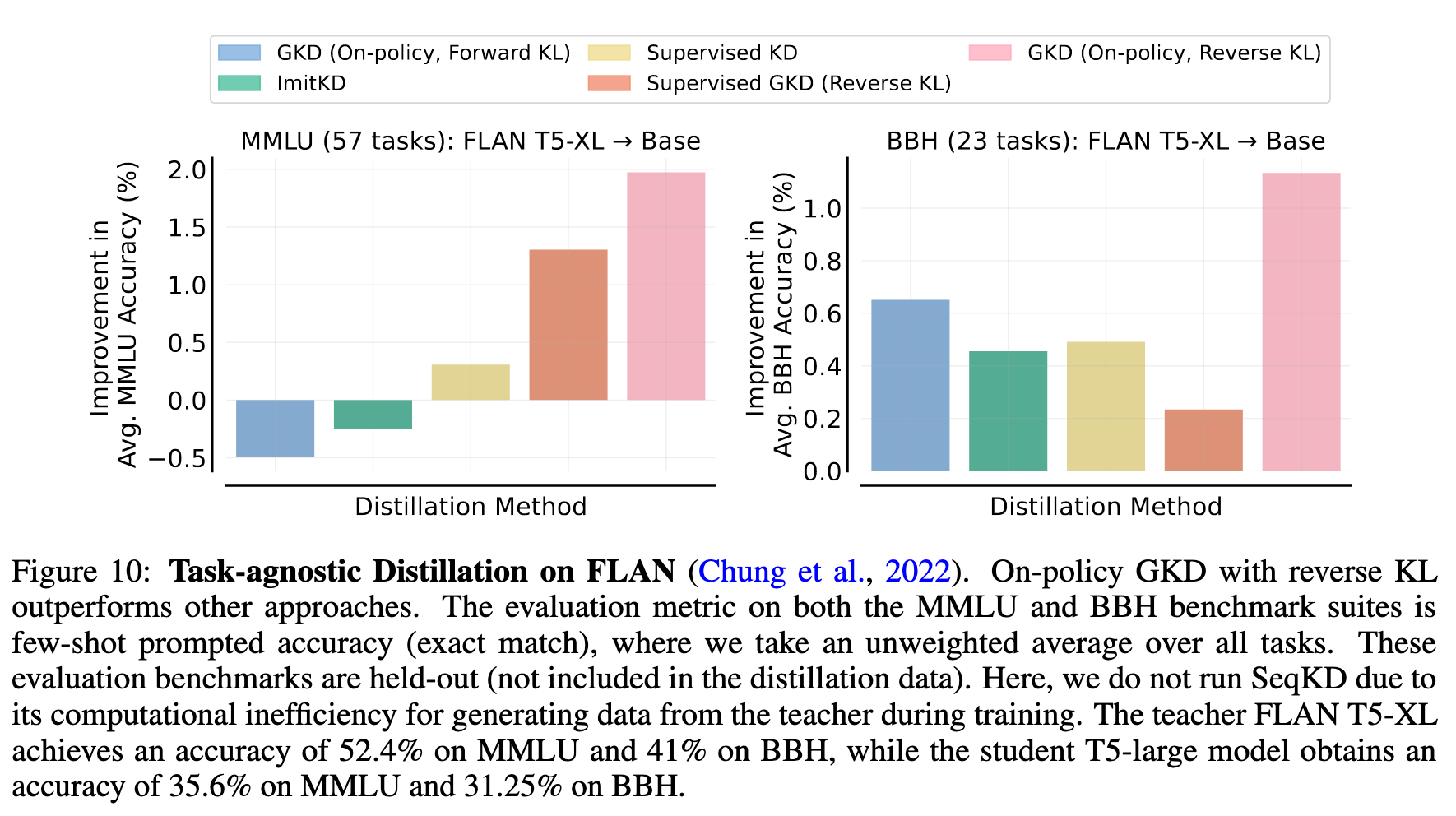
2.5 Task-agnostic Distillation
3. 笔者总结
-
感觉 On-Policy Distillation 和 RL 中的 On-Policy 有些相似。教师模型就类似于奖励模型。实际上,Qwen3 Technical Report 里面 Table 21 做了 On-Policy Distillation 和 RL 的对比实验。
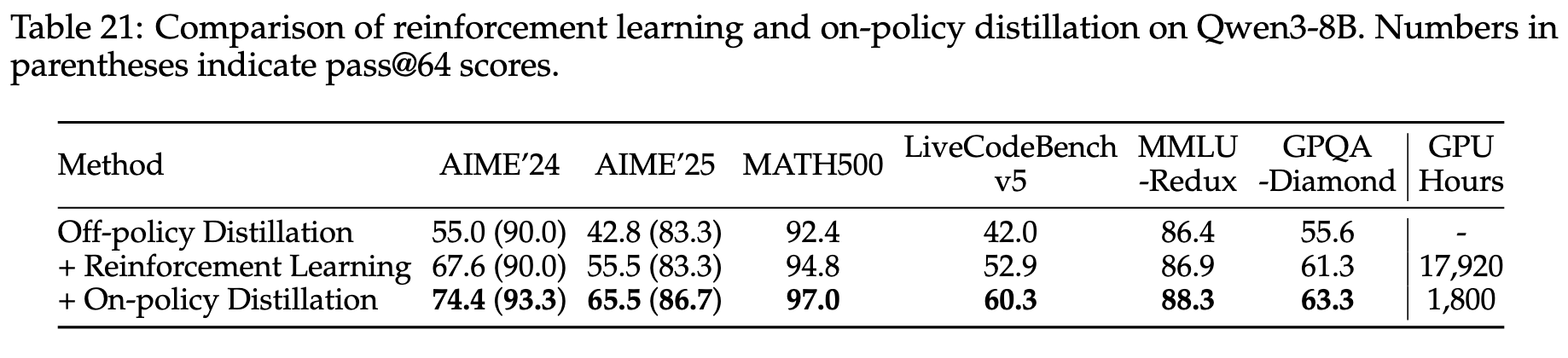
-
所以说 “Off-Policy Distillation” 和 “On-Policy Distillation” 是不是可以同时用来对学生模型进行蒸馏?没有绝对的好坏。 -
GKD 就是通过超参数来控制训练数据中学生模型生成序列的比重,实现缓解 model-covering 的问题。然后对 divergence 进行了一般化。
4. References
-
On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes -
Qwen3 Technical Report








