
标题: rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking[1]
FROM ICML 2025 oral arXiv GitHub
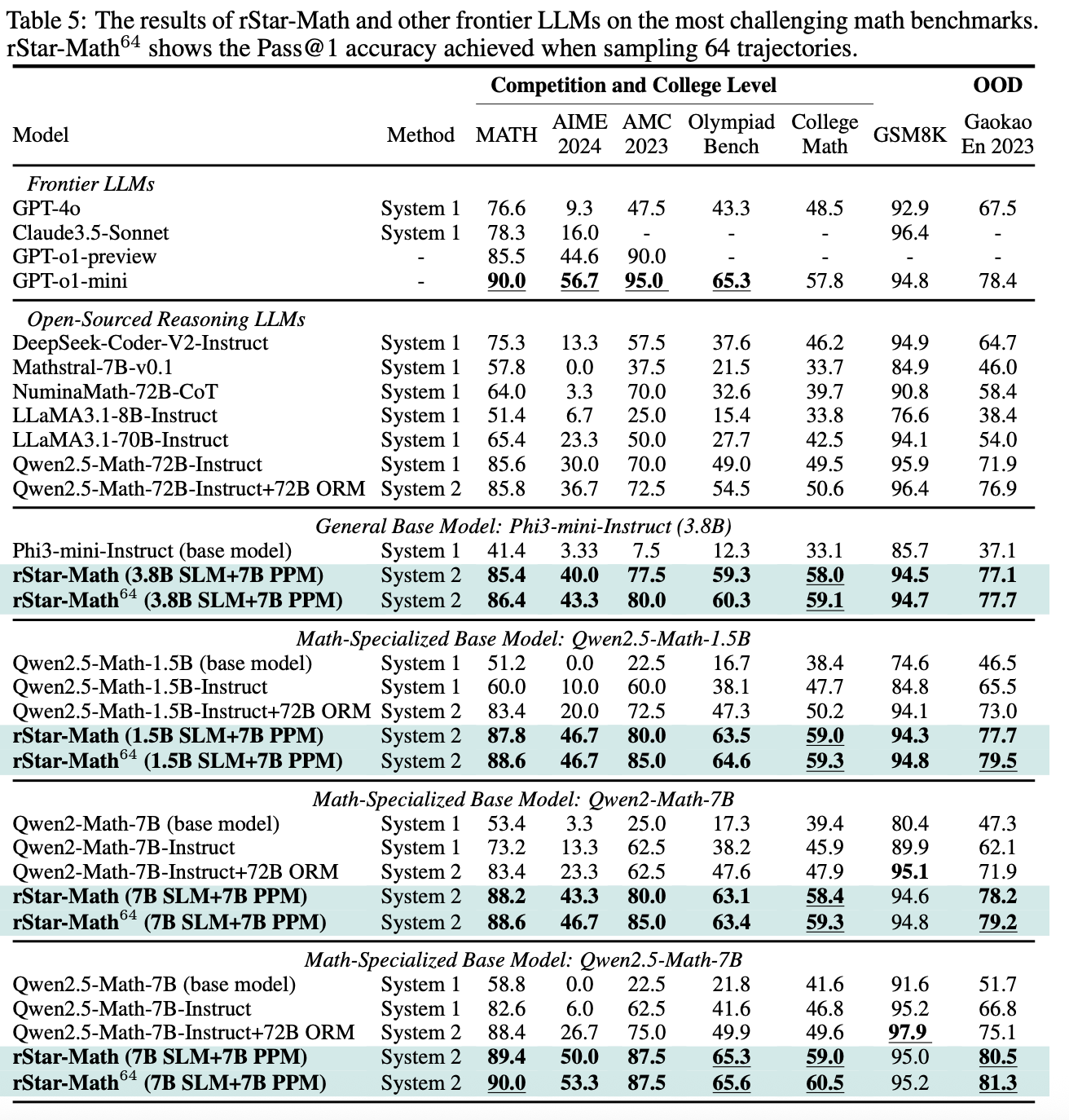
rStar-Math 极大提高了小模型(SLM)的数据推理能力。e.g. Qwen2.5-Math-7B 58.8% -> 90.0% on MATH[2]。超过了 Qwen2.5-Math-72B-Instruct,和 OpenAI o1-mini 相当。恐怖如斯
没有使用更大的模型进行蒸馏。而是通过 Monte Carlo Tree Search (MCTS) 来训练一种 deep thinking 的能力,通过迭代来生成质量越来越高的数据,实现 self-evolution。
既然是 deep thinking,那就会用到 CoT。而对于数学数据而言,结果正确并不能保证解题步骤正确。这些结果正确但解题步骤错误的数据会大幅降低数据质量。
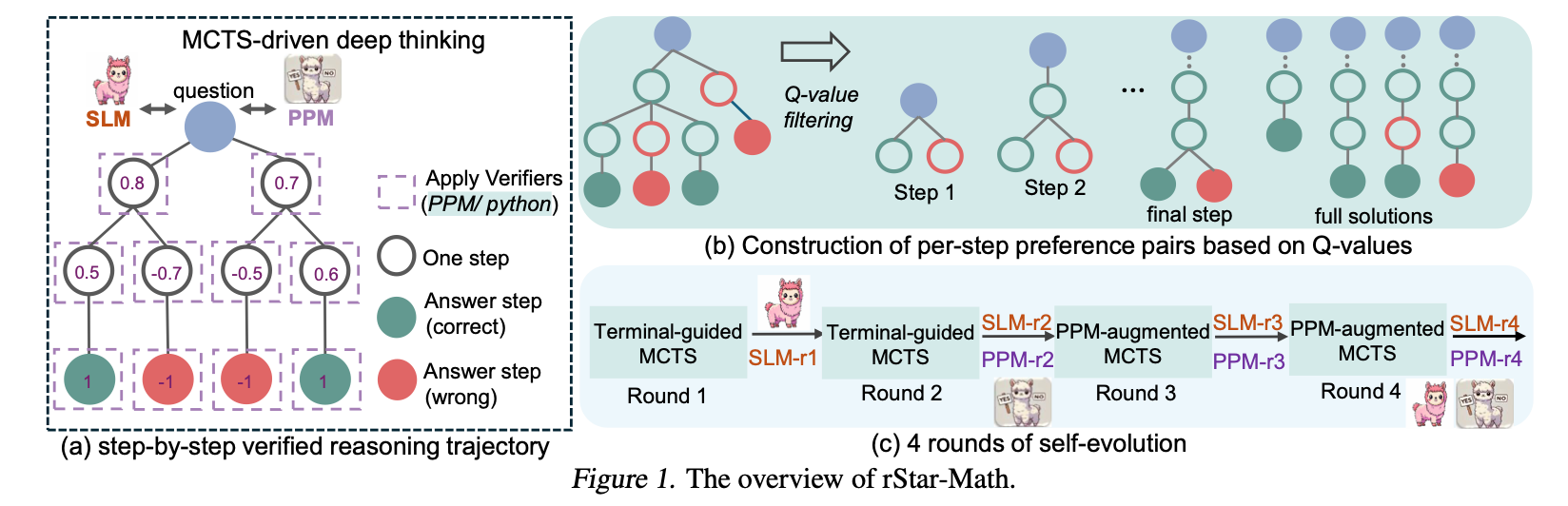
解数学题的过程就是一个 rollout,解题步骤组成 trajectory。每个步骤都会用一个 code-augmented CoT 来生成一个对应的 Python 代码。policy model 在进行采样时,只会将代码能正确执行的步骤作为候选节点🐮。并且对那些让更多 trajectory 产生正确结果的步骤赋予更大的 Q-value。
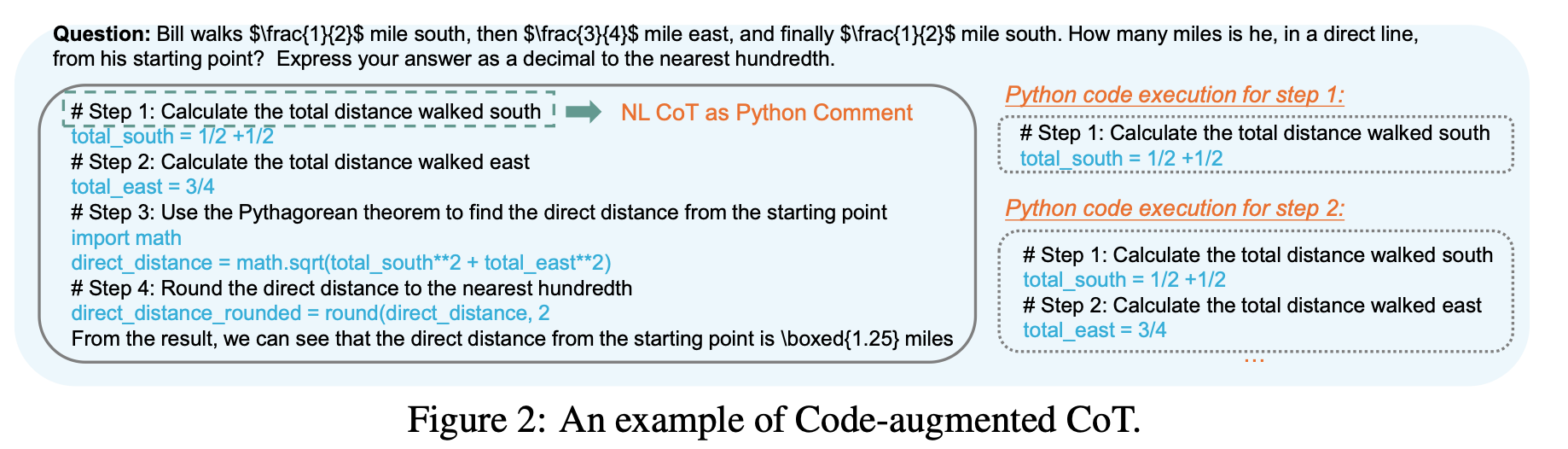
尽管 Q-value 不能作为每个步骤的准确得分,但它可以区分步骤的类别(正确/错误/无关),以用来为每个步骤构建偏好对。然后结合 pairwise ranking loss 来优化 PPM(process preference model) 对每个步骤的得分预测。 感觉这里叫 steps preference model 更好理解一点😂

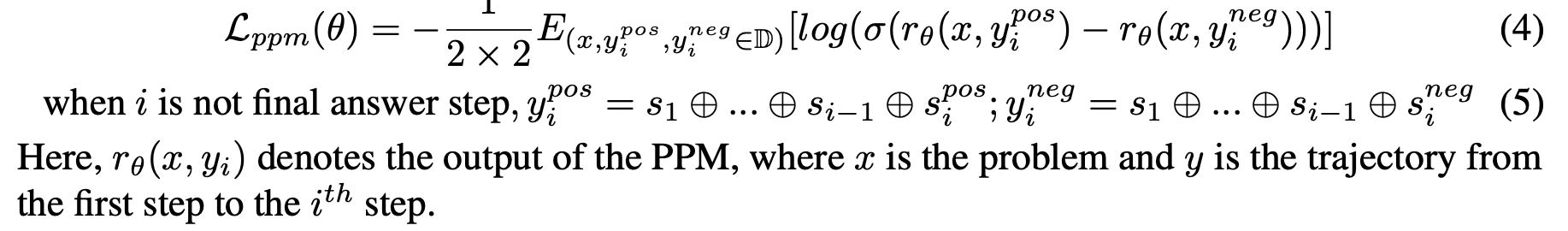
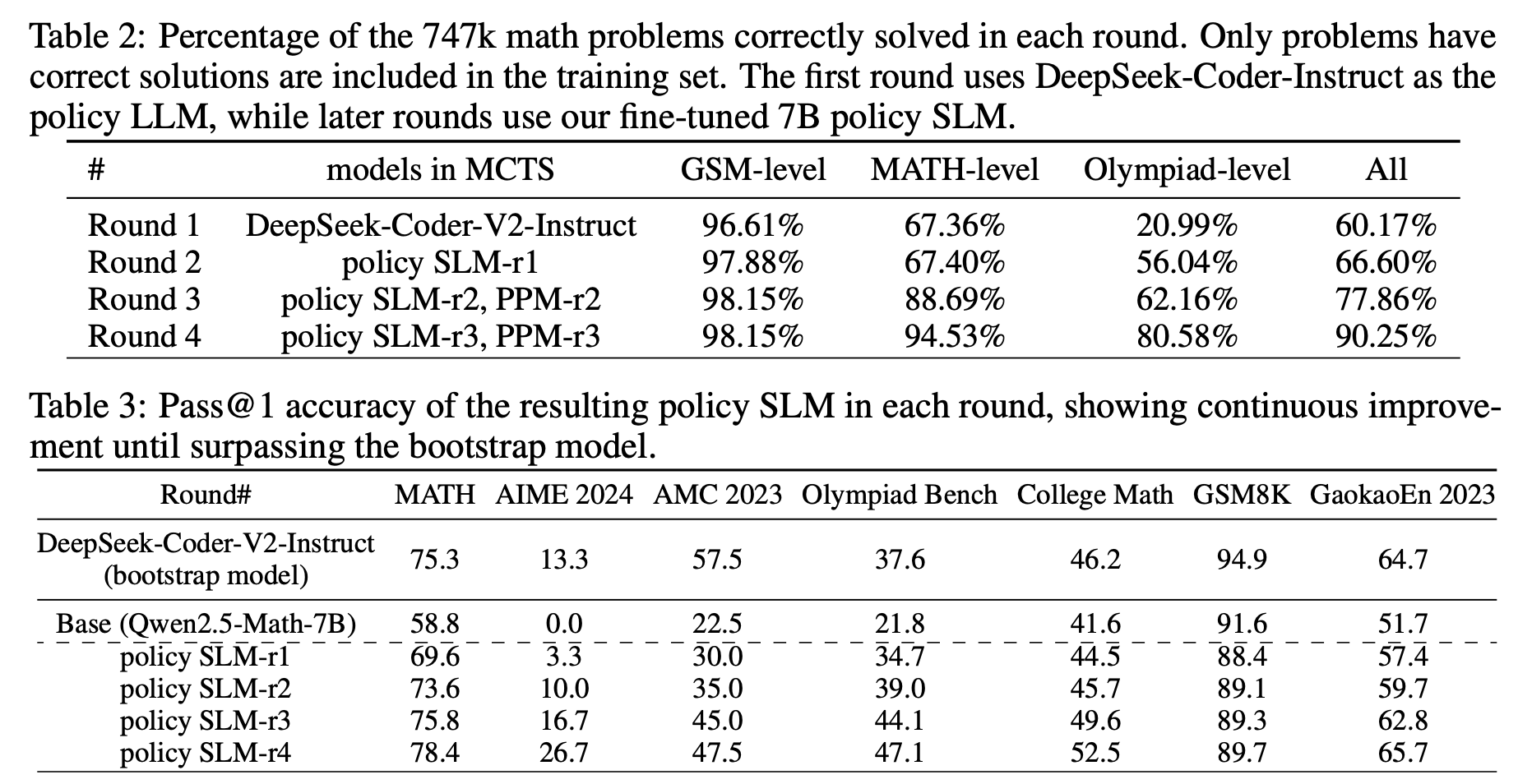
作者首先构建了一个 747k 的数学数据集(主要来自 NuminaMath[3] 和 MetaMath[4]),作为起点,进行 four-round self-evolution。在每一轮都用上一轮得到的 policy model 和 PPM 进行 MCTS,每一轮都会生成更高质量的数据。就这样左脚踩右脚。
笔者想法:
-
为什么是 four-round?更多的 round 不好吗?模型开始是通过 747k 数据训练 base model,然后两种创新性的方法👍迭代 policy model & PPM。过程中并没有引入新的数据集,全靠模型生成。所以感觉模型搜索空间是有限的。或许 4 轮就可以让模型收敛。 -
FROM Reviewer nzwK: 采样可以正确执行代码的步骤可以很大程度上提高数据质量,但这样无法识别逻辑错误👍。 -
值得一提的是,作者在 round-1 使用 DeepSeek-Coder-V2-Instruct-236B 作为引导。虽然这种方式不是蒸馏,但可以看作是一个更大的模型来引导小模型的思考。在这个基础上实现的 self-evolution。而不是在原来的 such as Qwen2.5-Math-7B 上进行 self-evolution。所以感觉这是变相的提高了原始 base model 的能力😯。
References:
-
rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking -
Let’s Verify Step by Step -
Numinamath -
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
最后附上两张文章中的 Prompt Examples


注:若本文中存在错误或不妥之处,欢迎批评指正。








